Domain model purity vs. domain model completeness (DDD Trilemma)
I’ve been meaning to write this article for a long time and, finally, here it is: the topic of domain model purity versus domain model completeness.
Domain model completeness
In this article, we’ll talk about a trilemma that comes up in each and every project. In fact, I received a dozen or so questions about this trilemma during the last year or two (slightly embarrassing to realize how long some article ideas spend in my write-up queue).
To best describe this trilemma, we need to take an example. Let’s say that we’ve got a user management system with one use case so far: changing the user email. Here’s how the User domain class looks:
public class User : Entity
{
public Company Company { get; private set; }
public string Email { get; private set; }
public Result ChangeEmail(string newEmail)
{
if (Company.IsEmailCorporate(newEmail) == false)
return Result.Failure("Incorrect email domain");
Email = newEmail;
return Result.Success();
}
}
public class Company : Entity
{
public string DomainName { get; }
public bool IsEmailCorporate(string email)
{
string emailDomain = email.Split('@')[1];
return emailDomain == DomainName;
}
}
And this is the controller that orchestrates this use case:
public class UserController
{
public string ChangeEmail(int userId, string newEmail)
{
User user = _userRepository.GetById(userId);
Result result = user.ChangeEmail(newEmail);
if (result.IsFailure)
return result.Error;
_userRepository.Save(user);
return "OK";
}
}
This is an example of a rich domain model: all business rules (also known as domain logic) are located in the domain classes. There’s one such rule currently — that we can only assign to the user an email that belongs to the corporate domain of that user’s company. There’s no way for the client code to bypass this invariant — a hallmark of a highly encapsulated domain model.
We can also say that our domain model is complete. A complete domain model is a model that contains all the application’s domain logic. In other words, there’s no domain logic fragmentation.
Domain logic fragmentation is when the domain logic resides in layers other than the domain layer. In our example, the UserController (which belongs to the application services layer) doesn’t contain any such logic, it serves solely as a coordinator between the domain layer and the database.
Domain model purity
Let’s now say that we need to implement another business rule: before changing the user email, the system has to check whether the new email is already taken.
Here’s a common way to verify the email uniqueness:
// UserController
public string ChangeEmail(int userId, string newEmail)
{
/* The new validation */
User existingUser = _userRepository.GetByEmail(newEmail);
if (existingUser != null && existingUser.Id != userId)
return "Email is already taken";
User user = _userRepository.GetById(userId);
Result result = user.ChangeEmail(newEmail);
if (result.IsFailure)
return result.Error;
_userRepository.Save(user);
return "OK";
}
This gets the job done, but this solution introduces domain logic fragmentation. The domain layer no longer contains all the business rules, one of them has drifted to the controller. It’s also possible now to change the user email without checking for its uniqueness first, which means our domain model is not fully encapsulated.
Is there a way to restore domain model completeness?
There is. We can move the responsibility to verify the email uniqueness inside the User class, like this:
// User
public Result ChangeEmail(string newEmail, UserRepository repository)
{
if (Company.IsEmailCorporate(newEmail) == false)
return Result.Failure("Incorrect email domain");
User existingUser = repository.GetByEmail(newEmail);
if (existingUser != null && existingUser != this)
return Result.Failure("Email is already taken");
Email = newEmail;
return Result.Success();
}
// UserController
public string ChangeEmail(int userId, string newEmail)
{
User user = _userRepository.GetById(userId);
Result result = user.ChangeEmail(newEmail, _userRepository);
if (result.IsFailure)
return result.Error;
_userRepository.Save(user);
return "OK";
}
This version gets rid of domain model fragmentation, but at the expense of another important property: domain model purity. A pure domain model is a model that doesn’t reach out to out-of-process dependencies. To be pure, domain classes should only depend on primitive types or other domain classes.
In our example, we’ve lost purity because the User now talks to the database. And no, replacing UserRepository with an IUserRepository interface won’t help:
public Result ChangeEmail(string newEmail, IUserRepository repository)
Replacing it with a delegate won’t help either:
public Result ChangeEmail(string newEmail, Func<string, bool> isEmailUnique)
Both of these alternatives still make the User class reach out to the database, and thus don’t bring domain model purity back.
This is where the choice between domain model completeness and purity comes from. You can’t have both at the same time.
The trilemma
Then why did I call it trilemma and not dilemma? That’s because there’s a third component here, application performance, and sometimes you can give it up in favor of having both domain model purity and completeness.
In theory, you could load all the existing users into memory and pass them to User as an argument:
// User
public Result ChangeEmail(string newEmail, User[] allUsers)
{
if (Company.IsEmailCorporate(newEmail) == false)
return Result.Failure("Incorrect email domain");
bool emailIsTaken = allUsers.Any(x => x.Email == newEmail && x != this);
if (emailIsTaken)
return Result.Failure("Email is already taken");
Email = newEmail;
return Result.Success();
}
// UserController
public string ChangeEmail(int userId, string newEmail)
{
User[] allUsers = _userRepository.GetAll();
User user = allUsers.Single(x => x.Id == userId);
Result result = user.ChangeEmail(newEmail, allUsers);
if (result.IsFailure)
return result.Error;
_userRepository.Save(user);
return "OK";
}
This version’s domain model is pure — User now only depends on other users. It is also complete — all the validations are located in the domain layer. But of course, it’s not practical from the performance standpoint, because we have to query all existing users on each email modification.
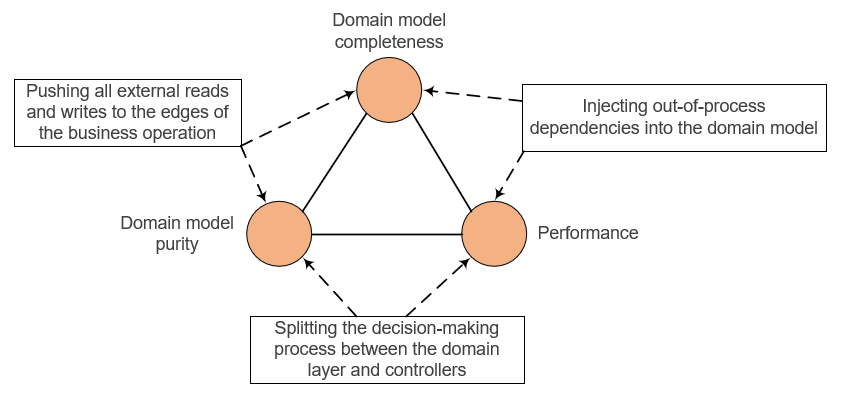
That’s where the trilemma comes into play. You can’t have all 3 of the following attributes:
-
Domain model completeness — When all the application’s domain logic is located in the domain layer, i.e. not fragmented.
-
Domain model purity — When the domain layer doesn’t have out-of-process dependencies.
-
Performance, which is defined by the presence of unnecessary calls to out-of-process dependencies.
You have 3 options here, but each of them only gives you 2 out of the 3 attributes:
-
Push all external reads and writes to the edges of a business operation — Preserves domain model completeness and purity but concedes performance.
-
Inject out-of-process dependencies into the domain model — Keeps performance and domain model completeness, but at the expense of domain model purity.
-
Split the decision-making process between the domain layer and controllers — Helps with both performance and domain model purity but concedes completeness. With this approach, you need to introduce decision-making points (business logic) in the controller.
The first approach (pushing external reads and writes to the edges of a business operation) is sometimes acceptable. It works best when a business operation naturally follows the read-decide-act structure, where it has three distinct stages:
-
Retrieving data from storage
-
Executing business logic
-
Persisting data back to the storage
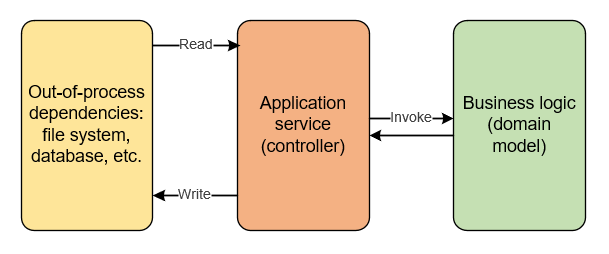
This is what we had in the initial version of our user management system, before we introduced the check for email uniqueness.
There are a lot of situations where these stages aren’t as clearcut, though. You might need to query additional data from an out-of-process dependency based on an intermediate result of the decision-making process. Writing to the out-of-process dependency often depends on that result, too.
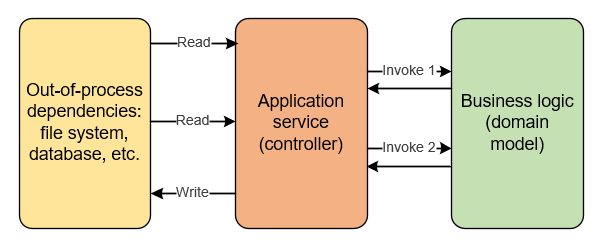
Or, like in our case, you might not be able to query the data necessary to make a decision in the domain model at all, because that’s simply not practical. Because of that, the first approach is usually out of the question.
The decision, then, comes down to the choice between the second (injecting out-of-process dependencies into the domain model) and the third (splitting the decision-making process between the domain layer and controllers) options.
Which one is better?
I strongly recommend that you choose domain model purity over domain model completeness, and go with the third approach: splitting the decision-making process between the domain layer and controllers. Domain logic fragmentation is a lesser evil than merging the responsibilities of domain modeling and communication with out-of-process dependencies.
Business logic is the most important part of the application. It’s also the most complex part of it. Mixing it with the additional responsibility of talking to out-of-process dependencies makes that logic’s complexity grow even bigger. Avoid this as much as possible. The domain layer should be exempted from all responsibilities other than the domain logic itself.
Splitting the decision-making process between the domain layer and controllers is the approach which Functional Programming, Unit Testing, and (arguably) Domain-Driven Design all converge to, albeit for different reasons.
-
DDD advocates for this approach because it helps keep the application’s complexity manageable. As you know, DDD is all about Tackling Complexity in the Heart of Software, where "heart" means the domain model.
-
Functional Programming chooses this approach because it’s the only way to make your functions pure. Functional Programming is all about referential transparency and the avoidance of hidden inputs and outputs in the functional core of your application (querying the database, aka database I/O, is one of such hidden inputs).
-
Unit Testing advocates for it because pure domain model means testable domain model. Without the separation between business logic and communication with out-of-process dependencies, your tests will be much harder to maintain as you will have to setup mocks and stubs, and then check interactions with them.
In our sample project, splitting the decision-making process between the domain layer and controllers means putting the the email uniqueness check into the UserController instead of the User class.
UPDATE
As C. Shea mentioned in the comments, this trilemma can be called a CAP theorem for Domain Modeling. Love the analogy.
Summary
-
Domain model completeness is when your domain model contains all the application’s domain logic.
-
Domain logic fragmentation is the opposite of that — it’s when the domain logic resides in layers other than the domain layer.
-
-
Domain model purity is when your domain model doesn’t reach out to out-of-process dependencies.
-
In most use cases, you can’t have all 3 of the following attributes:
-
Domain model completeness
-
Domain model purity
-
Performance
-
-
There are three common approaches, but each of them only gives you 2 out of the 3 attributes:
-
Pushing all external reads and writes to the edges of a business operation — Preserves domain model completeness and purity but concedes performance.
-
Injecting out-of-process dependencies into the domain model — Keeps performance and domain model completeness, but at the expense of domain model purity.
-
Splitting the decision-making process between the domain layer and controllers — Helps with both performance and domain model purity but concedes completeness.
-
-
If you can push all external reads and writes to the edges of a business operation without much damage to application performance, choose this option.
-
Otherwise, choose domain model purity over completeness.
Other articles in the series
-
Domain model purity vs. domain model completeness (this article)
Subscribe
Comments
comments powered by Disqus







