Which collection interface to use?
Let’s talk about when to use which collection type and why.
1. The guideline, again
Last time, we discussed the following guideline:
-
Use the most generic types possible for arguments,
-
Use the most specific types possible for return values.
Or, to be more precise:
-
Use the most generic types for arguments, while keeping the method’s signature honest,
-
Use the most specific types for return values, while keeping the method’s signature honest.
Here’s this guideline in one picture:
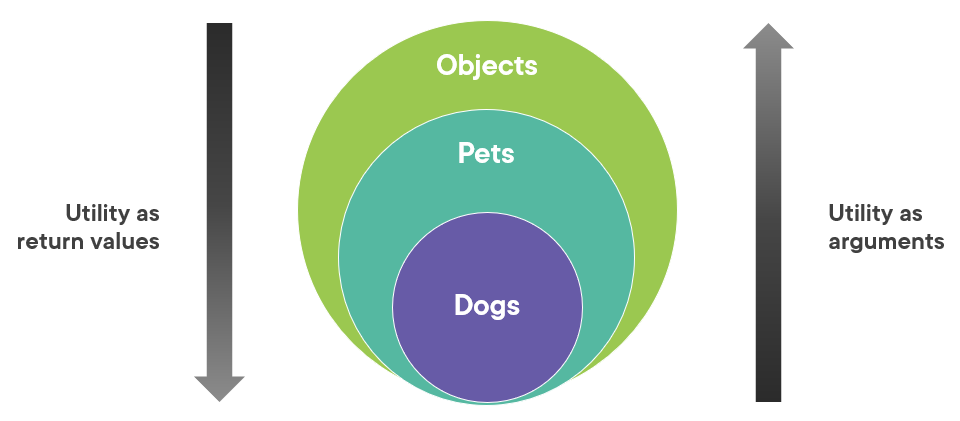
To summarize the reasoning behind it:
-
On the one hand, argument types provide the most utility when they are as generic as possible, because the method starts to apply to a wider range of input values.
-
On the other hand, return types provide the most utility when they are as specific as possible, because a specific return value exposes more functionality than a generic one.
2. Which collection type to return?
The use of collection types (and their interfaces) should also follow this guideline. You should also return the most specific and accept the most generic collection type.
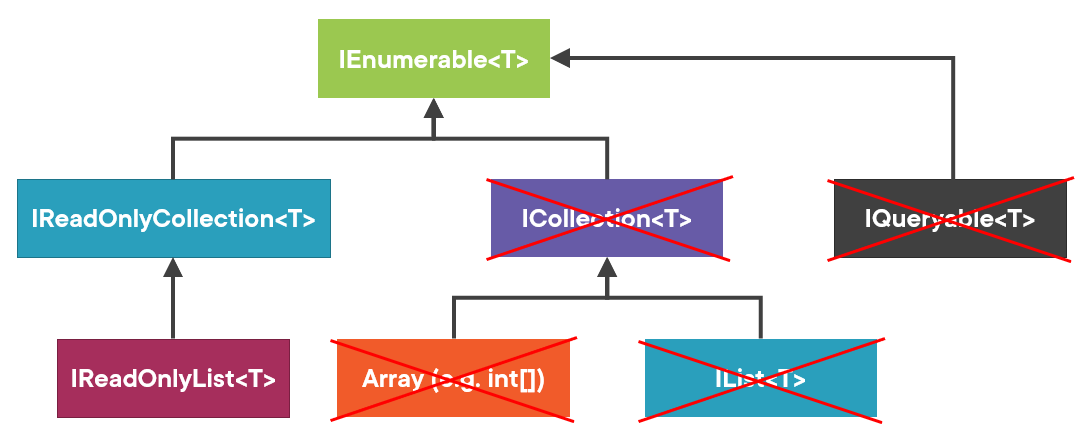
Here’s the collection interface hierarchy in .NET:
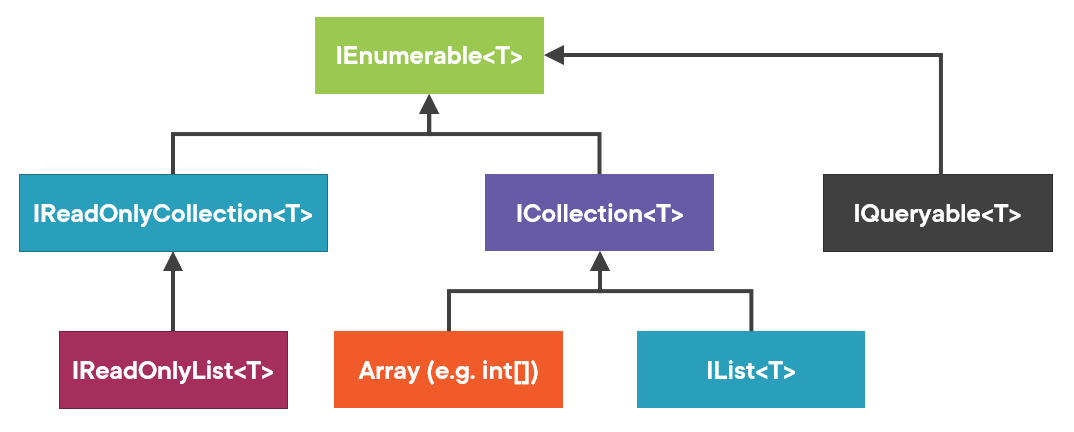
Note that it’s quite simplified, but good enough for our purposes. You can find the complete hierarchy diagram in this article: C# Read-Only Collections and LSP.
Given this hierarchy, which collection type should you use as a return value?
Well, following the guideline, it should be the most specific type, but which one exactly? There are multiple leaves in this hierarchy tree:
-
IQueryable -
IList -
Array(such asint[]) -
IReadOnlyList
Let’s discuss them one by one.
3. IQueryable is a leaky abstraction
The first option is IQueryable. This interface allows you to query the database using LINQ expressions the same way you would query an in-memory collection:

IQueryable interfaceThe difference here is that LINQ expressions that work with IQueryable are executed in the database, not in-memory. ORMs such as EF Core and NHibernate implement an IQueryable provider, which translates LINQ expressions into SQL queries.
You can think of IQueryable as an abstraction that allows you to work with different data sources the same way.
IQueryable is particularly popular in repositories, where you can introduce a GetAll method, like this:
// Student repository
public IQueryable<Student> GetAll()
{
return _context.Set<Student>();
}
And then use it to apply required filters in the controller:
// Student controller
public IEnumerable<StudentDto> GetAll()
{
var students = _repository.GetAll()
.Where(x => x.Email.EndsWith(".edu")); // Executed in the database
/* ... */
}
This approach looks logical at first. The client code (in our case, the controller) can build filters on top of IQueryable to its own liking, depending on the scenario. In the above example, for instance, we are selecting all students with .edu emails. This filter gets translated into SQL and is executed in the database, so there’s no excess data transfer between the database and our API.
But the use of IQueryable as a return value has a significant drawback: this interface is a leaky abstraction. As we discussed last time, a leaky abstraction is an abstraction that requires you to know implementation details it ought to abstract.
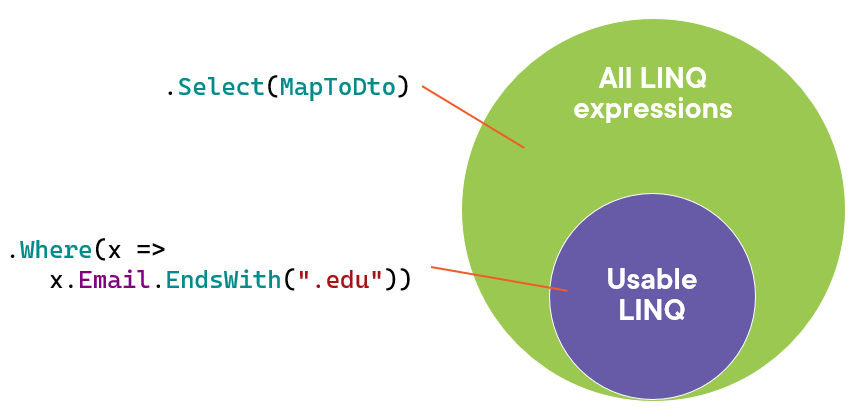
When using IQueryable, you have to know which LINQ expressions can be converted into SQL and which can’t. Look at this code:

IQueryable is a leaky abstractionHere, the EndsWith method can be translated into SQL, but MapToDto can’t. That’s why we first call ToList. This method prompts EF Core to execute the query we’ve built up so far and retrieve the resulting data into memory. All the subsequent LINQ expressions are executed against that in-memory data.
And that is exactly an example of a leaky abstraction. When using IQueryable, we have to know which LINQ expressions are supported by EF Core; we can’t simply execute any LINQ expression of our choice. In other words, we have to know how EF Core implements its IQueryable provider.
IQueryable interface is too broadAnd by the way, this is not the fault of EF Core (or NHibernate for that matter). ORMs do a great job supporting as many LINQ expressions as humanly possible. The problem is that the IQueryable interface itself is too broad. Its intention is to allow any LINQ expression to be translated into SQL, which is an impossible task to begin with. There’s an infinite number of LINQ expressions, and only so many of them can be converted into SQL.
Therefore, it is misleading to use IQueryable as part of the public API. It makes it seem as though you can apply any expression on top of this return value, but in reality, you have to keep in mind which LINQ expressions the ORM can understand.
The same is true when you accept an expression as an argument in a repository, like this:
// Student repository
public IQueryable<Student> GetAll(
Expression<Func<Student, bool>> predicate)
{
return _context.Set<Student>().Where(predicate);
}
Expressions, when used as part of the public API, are also leaky abstractions because they make it seem as though you can supply any LINQ expression to the method, whereas, once again, only a limited number of them can be understood by the ORM.
So, what’s the solution here?
The solution is to not use IQueryable (or expressions) as part of the repository’s public API. You can still use it internally, because the repository is aware of which ORM it works with and its limitations. But that knowledge shouldn’t cross the repository’s boundary. In other words, this knowledge shouldn’t leak to the clients of your repository; those clients shouldn’t be aware of the repository’s implementation details.
Here’s how we can do this:
// Student repository
public IEnumerable<Student> GetAll(string emailDomain)
{
IQueryable<Student> queryable = _context.Set<Student>();
if (string.IsNullOrWhiteSpace(emailDomain) == false)
{
queryable = queryable.Where(x => x.Email.EndsWith(emailDomain));
}
return queryable.AsEnumerable();
}
Notice that the filter is now represented as a plain emailDomain argument. There’s now no way to apply a filter that isn’t supported by the ORM. Also notice that we still use IQueryable, but only internally. We don’t leak it anywhere outside the repository.
The client code doesn’t have to know the internal implementation details of this method anymore. This method has become a good abstraction (as opposed to a leaky one).
4. IList and Array
Alright, so IQueryable is out of the question.
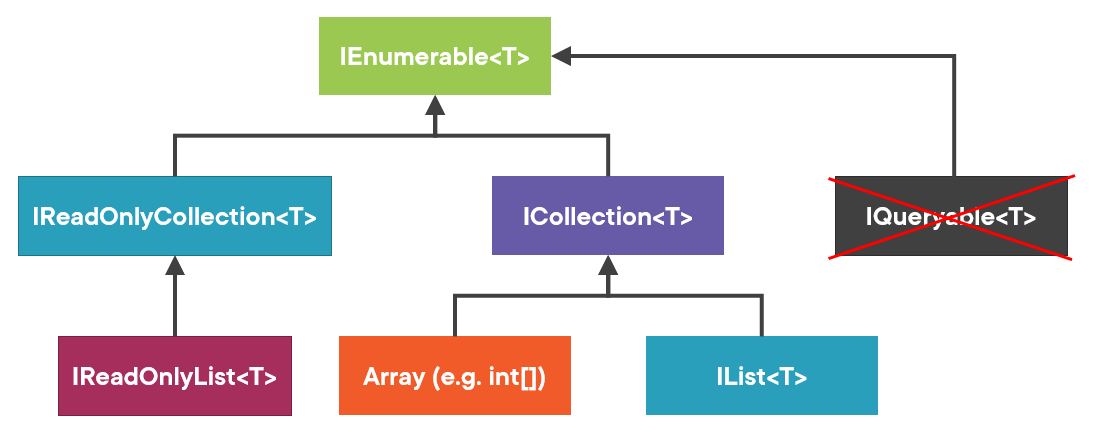
IQueryable as a return typeWhat about the other 3 leaves in the collection hierarchy tree?
-
IList -
Array(such asint[]) -
IReadOnlyList
Can we use IList or an array as the return value?
// Option 1
public IList<Student> GetAll(string emailDomain)
// Option 2
public Student[] GetAll(string emailDomain)
When deciding which type to use as a return value, we not only need to be cautious of leaking abstractions, but also need to consider whether this type correctly represents what the client can and can’t do with the return data.
For example, the client code can change a list of an array of students after it gets them from the repository:
IList<Student> students = _repository.GetAll(".edu");
students.Add(new Student()); // We can extend the collection
students[0] = null; // Or modify it
But what does it mean to change that collection?
You may do that for two reasons:
-
You are modifying the collection in order to add or remove students from the database.
-
You are reusing the collection for some other purpose. For example, you need to filter these students using some criteria and instead of creating a new collection, you are removing students from the collection you already have.
Both of these reasons are invalid.
Returning a mutable collection makes it seem as though the students it represents can be modified by simply adding or removing an element from that collection, which is not the case.
The moment the information about students leaves the database (as soon as SELECT SQL statement is finished), that information becomes detached from the database and modifying it doesn’t do anything.
Because of that detachment, we shouldn’t use a mutable collection, since it doesn’t properly represent what the client can and can’t do with the data in the database.
And you also shouldn’t modify the collection in order to reuse it for some other purpose, like filtration. Unless you have severe performance limitations (which is almost never the case), you should just create a new collection with the filtered data instead. Unnecessary data modification often leads to a whole set of hard-to-debug issues, which you can avoid simply by make that data immutable.
And so we should only use immutable collection types for both arguments and return values. There are 3 such types in this hierarchy:
Following the guideline, we should:
-
Use
IEnumerablefor arguments as the most generic type possible, -
Use
IReadOnlyListfor return values as the most specific type possible.
Here’s our GetAll method, refactored toward the use of IReadOnlyList:
// Student repository
public IReadOnlyList<Student> GetAll(string emailDomain)
{
IQueryable<Student> queryable = _context.Set<Student>();
if (string.IsNullOrWhiteSpace(emailDomain) == false)
{
queryable = queryable.Where(x => x.Email.EndsWith(emailDomain));
}
return queryable.ToList();
}
We use IReadOnlyList here instead of IEnumerable because IReadOnlyList provides more functionality out of the box. For example, it has the Count property and it also allows you to access the collection through an index. IEnumerable doesn’t have any of that, and you have to resort to LINQ extension methods to compensate for the lack of this functionality.
5. IEnumerable is also a leaky abstraction
So, we should use IReadOnlyList as the collection return type. But why do so many well-known libraries use IEnumerable instead? Even though it provides less functionality compared to IReadOnlyList?
One reason is lazy evaluation. In .NET BCL, most LINQ statements are evaluated lazily when working with IEnumerable.
Look at this example:
int[] numbers = new int[] { 1, 2, 3 };
IEnumerable<int> r1 = numbers.Where(x => x > 1); '1
IEnumerable<int> r2 = r1.Select(x => x + 1); '2
int result = r2.Sum(); '3
Here, the execution of lines '1 and '2 is postponed up to line '3. These LINQ statements are only evaluated when the whole thing needs to "collapse" in order to produce the end result. This happens when calling ToList(), Sum(), or similar.
If you need to maintain lazy evaluation, then use IEnumerable as the collection return type. Otherwise stick to IReadOnlyList.
5.1. IEnumerable with an ORM
Note that lazy evaluation also leads to IEnumerable being a leaky abstraction in some scenarios. Look at this code for example:

IEnumerable with an ORMThe code in the first line (and even in the second one) is only executed when we call ToList. If by that time the DbContext/ISession is already disposed of, we get an exception:

DbContext gets disposed of at the end of the methodThis is another example of a leaky abstraction. It’s a leaky abstraction because EF Core requires you to know whether the underlying database connection is still open at the time of IEnumerable evaluation.
In other words, EF Core imposes an additional, hidden precondition. This precondition is hidden because nowhere in the IEnumerable interface’s signature does it tell you to keep an eye on the database connection, and yet, EF Core does impose that requirement.
Note that the leakiness of the IEnumerable interface is a much smaller issue compared to IQueryable because the presence of a non-disposed DbContext (or ISession in case of NHibernate) is a reasonable assumption in most web applications. You will almost always have an active DbContext instance for the whole duration of the business operation; the DbContext is usually disposed of only at the end of that operation.
Still, the fact remains: lazy evaluation of database operations violates the LSP principle for the IEnumerable interface and makes the implementation of that interface a leaky abstraction. If you aren’t planning on using lazy evaluation, it’s best to stick to IReadOnlyList instead.
5.2. IEnumerable without an ORM
Note that implementations of IEnumerable often act as leaky abstractions even in scenarios without an ORM.
For example, BlockingCollection implements IEnumerable in such a way that it blocks the calling thread in method MoveNext() until another thread adds an element to that collection:
public void Test()
{
BlockingCollection<int> collection = new BlockingCollection<int>();
IEnumerator<int> enumerator = collection.GetConsumingEnumerable().GetEnumerator();
bool moveNext = enumerator.MoveNext(); // The calling thread is blocked
}
And there are countless implementations of IEnumerable that exhibit similar behavior. For example, you could write an infinite random number generator that implements IEnumerable<int>, like this:
private IEnumerable<int> Test2()
{
Random random = new Random();
while (true)
{
yield return random.Next();
}
}
If you call ToList on such an implementation, the program will hang in an infinite loop.
Note that technically, these implementations aren’t leaky abstractions, because the IEnumerable interface doesn’t promise collection finality (i.e. it doesn’t expose a Count property).
But still, in practice, most programmers expect a certain behavior from IEnumerable. Collection finality and non-blocking calls to MoveNext are part of that expectation. We can say that IEnumerable has an implicit contract that most programmers came to rely on, and some implementations of IEnumerable violate that contract and become leaky abstractions.
6. IEnumerable in library development
The guideline of returning the most specific type (such as IReadOnlyList) is relevant for enterprise application development, but the situation with library development is different.
If you are developing a library for a public use, you want to restrict its public API as much as possible to give yourself leeway to update that API. This includes both the number of available public methods and the types those methods return. In short, you want to promise as little as possible.
Returning IEnumerable over IReadOnlyList is preferable in such environment. It allows you to change the internal implementation from e.g List<T> to a LinkedList<T> without breaking backward compatibility.
But this doesn’t apply to regular enterprise application development. Since your team is the only user of your code, you don’t need to maintain backward compatibility and may refactor your code as needed if the API changes.
This is called the Open-Closed Principle. You can read more about it in this article: OCP vs YAGNI
7. Summary
-
Adhere to the following guideline.
-
Use
IEnumerablefor arguments as the most generic type possible. -
Use
IReadOnlyListfor return values as the most specific type possible.
-
-
IQueryableis a leaky abstraction because it requires you to know which LINQ expressions the ORM can understand. -
IListandArrayaren’t suitable because they are mutable. -
Keep in mind that some implementations of
IEnumerableare also leaky abstractions.
- ← Generic types are for arguments, specific types are for return values
- Storing information in its highest form →
Subscribe
Comments
comments powered by Disqus







