Database and Always-Valid Domain Model
Today, we’ll talk about an important question: how does the application database fit into the concept of Always-Valid Domain Model?
In other words, is the database part of the always-valid boundary or should you consider it an external system and validate all data coming from it?
1. Always-Valid Domain Model
Just a quick reminder on what Always-Valid Domain Model is. It’s a guideline saying that domain classes should always guard themselves from becoming invalid.
The main benefit of this guideline is that it helps alleviate a lot of maintenance burden. Once a domain object is created, you can be sure that it resides in a valid state. This removes all the second-guessing regarding whether you validated it or not; you simply can’t instantiate an invalid domain object.
To adhere to this guideline, you need to maintain a clear boundary between the (always-valid) domain model and the (not-always-valid) external world:
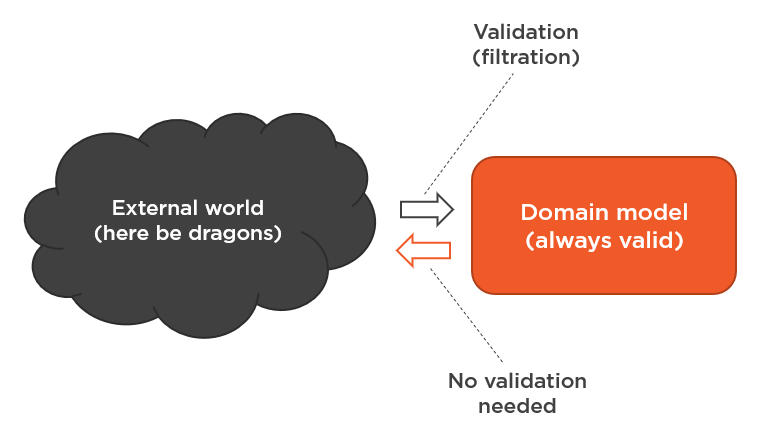
2. Always-valid boundary and the database
Now the question is: where does the database belong on the above diagram? Is it part of the external world or is it part of the always-valid boundary?
In other words, should you trust the data in your database to be valid? Or should you validate it each time you query it?
Treat the database as part of the always-valid boundary
Treat your database the same way you treat the domain model:
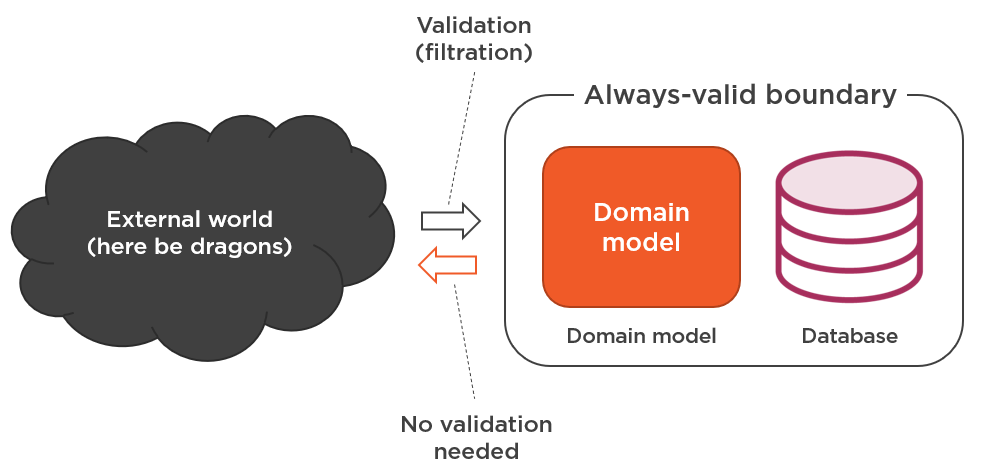
View the database as part of your application, and any data in it — as fully validated.
This is the same approach you take with the private fields of your domain classes. You don’t validate data in those fields on each reading. In an always-valid domain model, validation is performed prior to changing state, not after. After the change is persisted, it is assumed to be valid. The same is true for the application database.
Of course, this requires that no external application has access to your database, and no one changes its data manually. At the very least, such manual changes should be carefully audited to ensure they conform to all the validation rules.
It’s a good practice to avoid data tinkering and sharing your database with other applications anyway, so following these guidelines fits well with including the database into the always-valid boundary.
But what if you do share your database? How should it be treated then?
3. Always-valid boundary and a shared database
Sometimes, you just can’t have a dedicated database for your application. This might be due to historic reasons that you can’t do anything about, which is often the case in legacy applications.
What should you do then?
In this case, segregate parts of your database that are visible to other applications from parts that aren’t. Treat the visible portion as part of the external world; the invisible one — as part of the always-valid boundary.
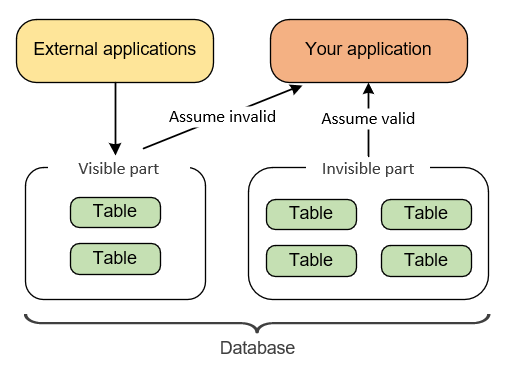
In other words, you should assume that any data coming from the shared portion of the database may be incorrect. This portion of the database essentially becomes an additional source of external input, similar to the user input. You can’t trust that input and should always validate it.
4. Managed vs unmanaged dependencies
This guideline of treating the application database as part of the always-valid boundary extends to all out-of-process dependencies interactions with which aren’t visible to external applications. I call such dependencies managed dependencies.
For instance, the file system is another typical example of a managed dependency. If your application writes to and reads from files on the disk and no other application can access them, then those files also become part of the always-valid boundary. Data is such files can be assumed valid.
On the other hand, input from unmanaged dependencies (out-of-process dependencies interactions with which are visible to external applications) should always be validated. A typical example here are messages coming from a message bus.
5. Guarding vs validating
Note that it’s not to say that you can’t ever guard against data coming from the application database. You can. Keep in mind though that the concept of guarding is different from validation.
I explained it in more detail in my Always-Valid Domain Model article, but here’s an image that summarizes the differences:
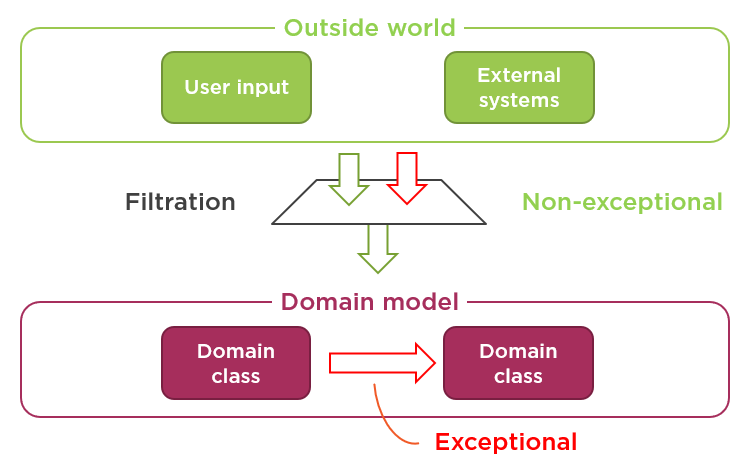
The input coming from the outside of the always-valid boundary (displayed as the domain model on this diagram) should be filtered out before passing it further to the domain model. It’s the first line of defense against data inconsistency. At this stage, any incorrect data are permitted and met with a polite "try again".
But once the filtration has confirmed that the incoming data is valid, all bets are off. When the data enters the always-valid boundary, it is assumed to be valid and any violation of this assumption means that you’ve introduced a bug.
Guards help you to reveal those bugs. They are the failsafe mechanism, the last line of defense that ensures data in the always-valid boundary is indeed valid. Unlike validations, guards throw exceptions; they comply with the Fail Fast principle.
How does this guarding look in practice when it comes to data in the application database? Look at this code sample:
public class Customer : Entity
{
private string _name;
public virtual CustomerName Name
{
get => (CustomerName)_name; // Throws if conversion fails
set => _name = value;
}
}
Here, we are using NHibernate to materialize data into the Customer. NHibernate (as well as EF Core) bypasses the constructor and uses reflection to assign the customer name directly to the _name private field.
Since our database isn’t shared with other applications, we can assume that the customer name string always complies with the CustomerName's validation rules. Therefore, we can use the unsafe conversion from string to CustomerName value object:
get => (CustomerName)_name;
It is unsafe because it throws an exception if the conversion fails. This is how the guarding may work between the domain model and the application database.
Here’s another example which uses EF Core instead of NHibernate:
public class Student : Entity
{
public Email Email { get; private set; }
}
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
modelBuilder.Entity<Student>(x =>
{
// Calling .Value throws if conversion from string to Email fails
x.Property(p => p.Email)
.HasConversion(p => p.Value, p => Email.Create(p).Value);
}
In this example, we are using EF Core’s Value Conversions feature to convert between string and the Email value object. The conversion from string to Email here is also unsafe because calling .Value in
Email.Create(p).Value
throws an exception if the string is not a valid email.
6. The use of ORMs within and outside of the always-valid boundary
There’s a common question about how to use an ORM within and outside of the always-valid boundary. It goes something like this:
According to principles of encapsulation, Entities and Value Objects need to stay in valid states. I use factory methods for creation to ensure that.
My problem is with the ORM. When an entity is read from the database, the ORM fills in the backing fields, it bypasses the create method and with that the validation.
How to make the ORM (EF Core or NHibernate) not bypass all the checks when creating domain objects?
As we discussed previously, it’s perfectly fine for an ORM to bypass the constructor or the factory methods because the application database is part of the always-valid boundary. Just as you don’t validate data in domain objects' private fields, you shouldn’t validate it coming from the application database.
But what about a shared database, where the validation is required? How can you use an ORM to do so?
For a shared database, you shouldn’t use an ORM at all. Again, treat data in shared databases as another source of external input. Create data contracts (DTOs) for that input and validate it explicitly on each querying.
7. Summary
-
Treat the application database as part of the always-valid boundary
-
If the database is shared with other applications, segregate parts of it that are visible to other applications from parts that aren’t
-
Treat the visible portion as part of the external world that should be validated
-
Treat the invisible portion as part of the always-valid boundary that shouldn’t be validated
-
-
This guideline extends to all managed dependencies, including the file system
-
You can still guard against data coming from the application database
-
Guarding is a failsafe mechanism
-
Validation is a filtration mechanism
-
-
Don’t use an ORM when working with a shared database
8. Related
Subscribe
Comments
comments powered by Disqus







