Always-Valid Domain Model
UPDATE 5/13/2021: the course has been published, check it now here: Validation and DDD.
I’m working on a new Pluralsight course on the topic of validation and DDD, with the help of the FluentValidation library and .NET data annotations (attributes). So expect a couple of posts about validation in the near future.
In the preparation for the course, I was re-reading some old articles about always-valid domain models, including this one form Jeffrey Palermo and the response to it from Greg Young. I highly recommend that you read them both if you haven’t already. This post is another response to Jeffrey’s article, which will hopefully complement Greg’s one.
1. Not-always-valid domain model
It may seem strange to write a response to an 11 years old article, but the concepts it talks about are timeless and still relevant today. Moreover, I still see people asking the same questions raised in that article and coming to the same conclusions, which in my opinion are incorrect. I also haven’t seen a complete rebuttal anywhere (Greg’s rebuttal is great but not complete), so I decided to write my own.
To recap the whole debate, Jeffrey writes that creating a domain entity that guards itself against ever becoming invalid is impractical for the following reasons:
-
Validation rules are context-dependent and can’t be equally applied across all use cases.
-
The message returned during the validation is the responsibility of the presentation layer and should not reside in the domain layer.
-
Existing validation rules may not apply to historical data.
Let’s discuss these points one by one.
2. Validation rules are context-dependent
This is the point Greg responds to in his article. The crux of his response is that:
-
There are invariants attached to each domain class — conditions that must be held true at all times. These invariants define the domain class: that class is what it is because of them. Therefore, you can’t possibly violate these invariants. If you do so, the domain class would simply cease being the thing you expect it to be; it’d become something else.
For example, a triangle is a concept that has 3 edges. The
edges.Count == 3condition is inherently true for all triangles. If you violate it by, say, adding the 4th edge, the object would become a square, not a triangle. Or, to take the example Greg brings up: a unicorn without a horn is a horse, not a unicorn. -
Reasoning about the domain model using invariants helps with the DRY principle. When there are multiple operations doing the same check, you have to be diligent to not miss it in any of those operations. Making the domain class itself responsible for that check absolves you of this additional mental burden and ensures that the check is always there.
These are great points. Especially the first one about invariants defining domain classes, and not the other way around. That’s something I personally missed when reading the post the first time many years back.
2.1. Validations vs invariants
But there’s also something that I think both Jeffrey and Greg are incorrect about: the difference between validations and invariants.
People often view input validation and invariants as different concepts. In fact, they are exactly the same. You wouldn’t validate input data if it weren’t for application invariants.
For example, the check for email address validity is there only because your problem domain requires all email addresses to adhere to certain rules. These rules are invariants: they define the concept of email address in your bounded context. Without them, the email address would cease being an email address. For instance, a string without an @ is not an email.
The difference between input validation and invariants is just a matter of perspective. To elaborate on this point, let’s look at the application from a hexagonal (or onion) architecture standpoint:
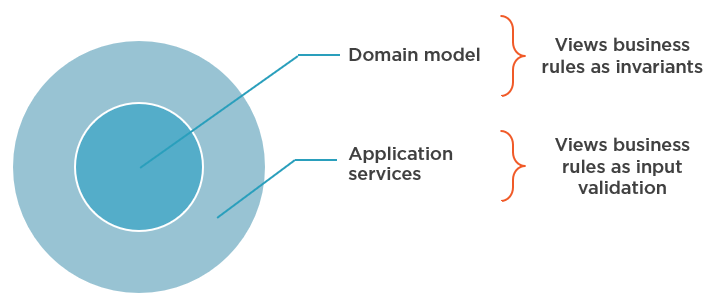
The same business rules affect both the domain model and application services, but in different ways. The domain layer views them as invariants, while the application layer — as input validation rules.
This difference leads to different treatment of violations of these business rules. An invariant violation in the domain model is an exceptional situation and should be met with throwing an exception. On the other hand, there’s nothing exceptional in external input being incorrect. You shouldn’t throw exceptions in such cases and instead should use a Result class.
Here’s a picture that will help you form a right mental model:
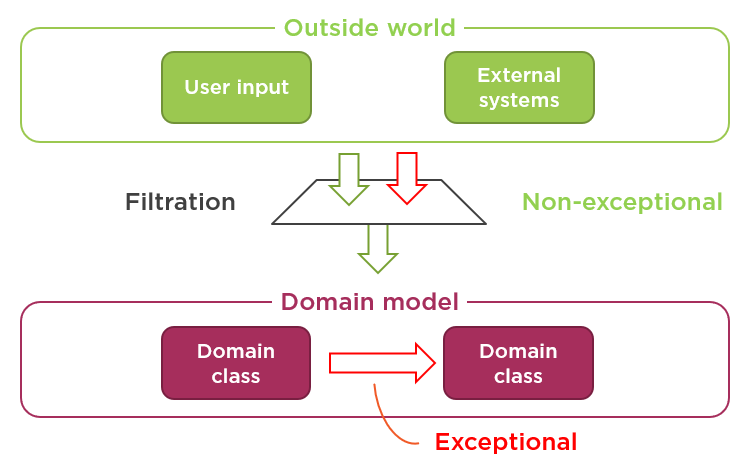
Any invalid input from external applications is filtered out before passing it further to the domain model. It’s the first line of defense against data inconsistency. At this stage, any incorrect data are permitted and met with a polite "try again".
But once the filtration has confirmed that the incoming data is valid, all bets are off. When the data enters the domain model boundary, it is assumed to be valid and any violation of this assumption means that you’ve introduced a bug. Such bugs are exceptional situations — the application should fail fast as soon as it encounters one.
How does this duality look in practice? Quite simple. Here’s an example:
// Controller
public string UpdateStudent(int studentId, string name)
{
if (string.IsNullOrWhiteSpace(name)
return "Name cannot be empty";
Student student = GetStudent(studentId);
student.UpdateName(name);
return "OK";
}
// Domain layer
public class Student
{
public void UpdateName(string name)
{
if (name == null)
throw new ArgumentNullException();
Name = name;
}
}
Notice how the controller checks the name of the student. This is the filtration in action: the controller returns an error message should the client pass an incorrect name. The Student domain class also contains the same check, but this check is not input validation — it’s an invariant check. Hence it throws an exception instead of using a return value.
This exception acts as the last line of defense. Its activation means that the filtration is not working properly in the controller and should be fixed. (Note that there are scenarios related to race conditions where the domain model should also use a return value instead of throwing an exception; check out this article for more details: Validation and DDD.)
2.2. Simple vs complex validations
I’ll throw another misconception into the mix while I’m at it (it wasn’t part of the original debate between Jeffrey and Greg).
Sometimes, people also differentiate between simple and complex validations. You may hear the former being called "data validation" and the latter — "business rules validation". By this logic, checking that the student email contains an @ would be data validation, while checking that you can enroll the student into a course — business rules validation.
This is incorrect. Data validation is the same as business rules validation. The only reason why they are being segregated is to rationalize having two ways of handling input validation: simple validations are normally tackled by frameworks such as FluentValidation or .NET data annotations (attributes), while complex validations — by controllers and command handlers.
You may also hear that complex validations have a business meaning, but simple validations don’t. This is also a misconception. All validations, not matter how simple, are a result of business requirements and the negotiation between those requirements and technical limitations. The only distinction here is that some validations are simpler than others.
This is not to say that you should only have one way of dealing with input validation. It makes sense to extract simple validations out of controllers because they clutter the program execution flow. On the other hand, it’s counterproductive to attribute complex validations to frameworks such as FluentValidation — this will fragment that flow and diminish code readability. But that’s just a matter of convenience, it doesn’t mean there are two types of input validation.
2.3. Context is part of the business rules
Now, back to the first point that validation rules are context-dependent.
It’s true that a lot of validations depend on the context they are invoked in. But it doesn’t mean that the entity needs to enter an invalid state before you can validate it. The context itself is part of the business rule.
For larger-scale contexts, we have the Bounded Context pattern, where you separate a real-world object into multiple representations that are best suited for a particular problem at hand. Each of these representations may exhibit different invariants, even though they all describe the same object in the real life.
Smaller-scale contexts should be encoded into the domain class itself. For example, let’s say that the system may enroll a student into a new course only if this student is active.
How can this be done?
The best way is to use the CanExecute pattern, like in the following example (I’ve omitted checks for studentId and courseId validity for brevity):
// StudentController
public string Enroll(int studentId, int courseId)
{
Student student = GetStudent(studentId);
Course course = GetCourse(courseId);
Result result = student.CanEnrollIn(course); '1
if (result.IsFailure)
return result.Error;
student.EnrollIn(course);
SaveStudent(student);
return "OK";
}
// Student
public Result CanEnrollIn(Course course)
{
if (Status != StudentStatus.Active)
return Result.Failure("Inactive students can't enroll in new courses");
return Result.Success();
}
public void EnrollIn(Course course)
{
Result canEnrollResult = CanEnrollIn(course); '2
if (canEnrollResult.IsFailure)
throw new InvalidOperationException(canEnrollResult.Error);
/* Enrollment logic */
}
In this example, the context is embedded into the Student itself: it knows when the enrollment is possible and when it is not.
This ensures that the domain knowledge (that only active students are eligible for enrollment in new courses) always remains in the domain layer. The domain layer:
-
Provides the API for the application layer to use this knowledge for input validation — The controller uses the
CanEnrollInmethod (line'1) to filter incoming data. -
Uses the same API for invariant check — The
Studentprotects that invariant in line'2by throwing an exception if enrollment is impossible.
Here are these two points on a diagram:
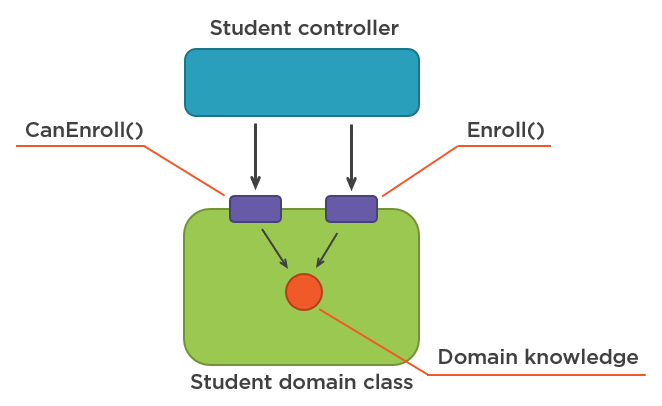
Student exposes the domain knowledge via the CanEnroll API. This API is then used by both the controller (to conduct input validation) and the Student itself (to protect its invariants).Domain classes should protect themselves from ever becoming invalid in any and all contexts. The context itself is part of the business rule; domain classes should be aware of that context when making decisions.
The protection can be done differently, though. The guard clauses in the example above is one way. An even better way is to rely on the type system.
For example, let’s say that there are two types of people in your CRM: students and instructors. Let’s also say that only students may enroll in courses and only instructors may start those courses. How would you implement this requirement?
One solution is to have a generic class Person that would combine both of these responsibilities:
public class Person
{
public PersonType Type { get; }
public void EnrollIn(Course course)
{
// Guard clause
if (Type != PersonType.Student)
throw new InvalidOperationException();
/* Enrollment logic */
}
public void Start(Course course)
{
// Guard clause
if (Type != PersonType.Instructor)
throw new InvalidOperationException();
/* Starting logic */
}
}
public enum PersonType
{
Student,
Instructor
}
Another solution is to introduce two classes, each responsible for their own operations only:
public class Person
{
}
public class Student : Person
{
public void EnrollIn(Course course)
{
/* Enrollment logic */
}
}
public class Instructor : Person
{
public void Start(Course course)
{
/* Starting logic */
}
}
The second solution is better because it provides a shorter feedback loop. With the first approach, an attempt to call Start() on a student would manifest itself as an exception at runtime. With the second approach, you wouldn’t be able to even compile such code. This is the Fail Fast principle taken to an extreme.
Check out this article to read more about strong typing vs guard clauses: C# and F# approaches to illegal state.
2.4. Data contracts vs domain model
I believe that the whole idea to make your domain model able to enter an invalid state stems from the conflation of data contracts (DTOs) and domain classes.
I wrote about this previously but it’s worth repeating: if you materialize the content of external requests directly into domain entities, it’s indeed hard to see how else you can validate that content if not for allowing those entities to enter an invalid state first.
The solution here is to separate your domain model from application data contracts, so that the two can vary independently. On top of that, with separate data contracts, you can refactor the domain model without breaking backward compatibility with client applications.
3. The text message is the responsibility of the presentation layer
Let’s move on to the next point: the message returned during the validation is the responsibility of the presentation layer and should not reside in the domain layer.
This is a good one. Indeed, if you look at the previous code sample:
// Student domain class
public Result CanEnrollIn(Course course)
{
if (Status != StudentStatus.Active)
return Result.Failure("Inactive students can't enroll in new courses");
return Result.Success();
}
you can see that the Student domain class is now responsible for the error text message.
This solution works fine in simpler use cases, but in general, such strings should be returned by the application or presentation layer, not the domain layer.
This is easy to fix, though. Introduce a separate Error class that would enumerate all possible errors in your application. Then convert Error instances into text messages in the presentation layer. Here’s what the domain class would look like after the refactoring:
// Student domain class
public UnitResult<Error> CanEnrollIn(Course course)
{
if (Status != StudentStatus.Active)
return Errors.InactiveStudentsCannotEnrollInNewCourses();
return Result.Success();
}
I wrote about this approach in-depth in this article: Advanced error handling techniques.
4. Validating historical data
Finally, we have the last point: existing validation rules may not apply to historical data.
For example, let’s say that your application didn’t require students to fill out their addresses, but now it does: any newly registered students must have a valid address.
What to do with the already existing students who didn’t fill in their address? Doesn’t it mean that these students will reside in an invalid state? Otherwise, how the system would even be able to continue working?
No, it doesn’t mean that those students need to reside in an invalid state. To elaborate on why, let’s step back for a moment and consider the options we’d have in this situation:
-
Remove all existing data that doesn’t comply with the new rules.
-
Make the
Studentclass handle both the old and the new sets of rules -
Create a separate
Studentclass for the new set of rules.
Of course, the first solution only works when you haven’t published your application to production yet. You can’t just delete production data.
The second option is what Jeffrey implicitly advocates for with not-always-valid domain entities. A better approach is to introduce a separate Student class specifically for the new rule set (option 3).
The situation when old data doesn’t comply with new business rules is called validation strengthening and requires a decision from the business as to how to deal with that old data. If the business decides to keep it, this decision should be explicitly reflected in the domain model: differentiate the old and the new data by introducing a separate class for the latter. Such introduction would create a transition period, during which you will have two sets of validation rules: the old one working for the pre-existing data and the new one — for data created from this point on.
In our particular example, you can create a subclass inheriting from Student that would require a valid address. Choose a term from the ubiquitous language for this class. For example, StudentWithAddress or any other term that domain experts use to differentiate such students. Once all students fill their addresses in, you can officially close the transition period by removing the old Student and renaming StudentWithAddress into just Student.
This article contains a more elaborate example of this technique: How to Strengthen Requirements for Pre-existing Data.
5. Dealing with huge UI forms
And the last point for today. Sometimes, you need to deal with large UI forms containing 10, 20 or even more fields. What if you want the users to be able to save the form half-way through and continue later? Doesn’t it mean the entity this form relates to will reside in an invalid state (assuming that all fields are mandatory for that entity)?
It would indeed be cruel to the users if they would have to erase their progress and start over again. But it doesn’t mean the corresponding domain entity must reside in an invalid state.
The ability to save the progress is another business decision. Just as for historical data, this business decision should be explicitly reflected in the domain model. Create another domain entity, say, StudentApplication that would have a much less strict set of invariants. Save this entity instead of Student. Once the user is done with the form and clicks "Register", do all the validations and convert the StudentApplication into a Student.
Though of course, nowadays, people normally split such large forms into several simpler ones — a wizard. But this only underlines the necessity to have an interim wizard (StudentApplication) entity because you need to save the progress.
6. Summary
-
Domain classes should always guard themselves against becoming invalid.
-
Invariants define the domain class: that class is what it is because of them.
-
Input validation and domain invariants stem from the same business rules. The difference between the two is a matter of perspective:
-
Business rules manifest themselves as invariants in the domain model.
-
Business rules manifest themselves as input validation in application services.
-
-
Invariant violation is an exceptional situation; use exceptions.
-
Invalid input is not an exceptional situation; use a
Resultclass. -
There’s no difference between "data validation" and "business rules validation". All validations, not matter how simple, are a result of business requirements.
-
The validation context is part of the domain knowledge and should reside in the domain model:
-
The domain model should provide an API for the application layer to use this knowledge for input validation.
-
The domain model should use the same API for invariant checks.
-
-
To remove text messages from the domain layer, use error codes instead of text and convert those code to text in the presentation layer.
-
To strengthen validation requirements, create a separate class that would handle the new set of rules. Once all existing data adheres to the new rules, remove the old class.
-
To deal with large UI forms that you need to save before submitting, create a separate entity with less strict validation rules.
7. Related
Subscribe
Comments
comments powered by Disqus







