How to handle unique constraint violations
Today, we’ll discuss how to best handle unique constraint violations.
What are unique constraint violations?
Unique constraints are a type of application invariants (conditions that must be held true at all times). There are two types of unique constraints: aggregate-wide and application-wide.
For instance, if a customer maintains multiple addresses, you may have a requirement that each such address must be unique. This is an example of an aggregate-wide constraint, where the Customer is an aggregate root and the Address is an internal entity.
It’s quite easy to enforce this type of uniqueness constraints. Aggregates define transactional boundaries and have full control over their content. Therefore, the enforcement boils down to putting a check to the AddAddress method in Customer — the customer already knows about all the currently existing addresses (they are loaded together as one aggregate) and can easily make the decision as to whether accept the new address or reject it.
On the other hand, a requirement for each customer to have a unique email address would be an example of an application-wide constraint. Such constraints span all customers and usually can’t be handled by the domain model (not unless you want to preserve domain model purity and application performance); they are handled by controllers (app services).
Here’s a typical example:
// CustomerController
public string ChangeEmail(int customerId, string newEmail)
{
// Check if there is another customer with the new email
Customer existingCustomer = _customerRepository.GetByEmail(newEmail);
if (existingCustomer != null && existingCustomer.Id != customerId)
return "Email is already taken";
Customer customer = _customerRepository.GetById(customerId);
customer.Email = newEmail;
_customerRepository.Save(customer);
return "OK";
}
This code works well in the vast majority of cases. The controller returns a validation error should the client pass an email that is already taken.
Handling race conditions
But what if there are two simultaneous requests that use the same email address for two different customers? That would lead to a race condition where the email uniqueness check passes for both of these requests and the controller tries to update both of the customers.
Of course, if you use a relational database, then you can protect your data integrity by introducing a unique index for the Customer.Email column that would reject one of the updates.
But still, even though the data in the database will be not be corrupted, one of the requests will result in an exception that would lead to a 500 (internal server) error. Of course, the correct behavior here is to return a 400 (bad request) error, not 500.
So how to best handle this situation?
First of all, you need to take into account how often such race conditions occur. If they are rare enough to the point that occasional 500 errors don’t bother your clients too much, then do nothing. Some errors are just not worth fixing.
If they do bother your clients or you anticipate the frequency of such race conditions to increase in the near future, then you need to transform these exceptions into 400 responses.
There are two main rules when it comes to exception handling:
-
Catch expected exceptions at the lowest level of the call stack and then convert them into
Resultinstances. -
Catch unexpected exceptions at the highest level of the call stack, log them and terminate the current operation.
Here’s an article where you can read more about these guidelines: exceptions for flow control.
You do expect unique constraint violations, so you need to catch the corresponding exceptions at the lowest level possible. But where exactly?
If you use an ORM, such as NHibernate or Entity Framework, then it’s going to be ISession.Dispose() (or ISession.Flush()) and DbContext.SaveChanges() respectively. Create your own wrapper on top of these methods and convert exceptions about uniqueness constraint violations into Result instances.
Notice that you shouldn’t just bluntly convert all exceptions coming from the database into results — only those you expect. It means that you need to test each use case to see what exact exceptions you are getting from the database. Those exceptions should be differentiated from all other potential exceptions.
Let’s say that this is the exception you are getting when trying to insert a duplicate customer email:
Msg 2627, Level 14, State 1, Line 2 Violation of UNIQUE KEY constraint 'IX_Customer_Email'. Cannot insert duplicate key in object 'dbo.Customer'. The duplicate key value is ([email protected]). The statement has been terminated.
The key part here is the constraint name (IX_Customer_Email). This constraint is what you need to look for in your wrapper:
// UnitOfWork is a wrapper on top of EF Core's DbContext
public class UnitOfWork
{
public Result SaveChanges()
{
try
{
_context.SaveChanges();
return Result.Success();
}
catch (SqlException ex)
{
if (ex.Message.Contains("IX_Customer_Email"))
return Result.Failure("Email is already taken");
// Other expected exceptions go here
throw;
}
}
}
This code only catches email duplication errors and re-throws all others.
Note that if you have more then one database exception you want to process, you can map them all into proper errors, like so:
public class UnitOfWork
{
public Result SaveChanges()
{
try
{
_context.SaveChanges();
return Result.Success();
}
catch (SqlException ex)
{
Maybe<Error> error = HandleException(ex);
if (error.HasNoValue)
throw;
return Result.Failure(error.Value);
}
}
private Maybe<Error> HandleException(SqlException exception)
{
if (exception.Message.Contains("IX_Customer_Email"))
return Errors.Customer.EmailIsTaken();
if (exception.Message.Contains("IX_Customer_UserName"))
return Errors.Customer.UserNameIsTaken();
// Other expected exceptions go here
return null;
}
}
This is what the controller looks like after this modification:
public string ChangeEmail(int customerId, string newEmail)
{
Customer existingCustomer = _customerRepository.GetByEmail(newEmail);
if (existingCustomer != null && existingCustomer.Id != customerId)
return "Email is already taken";
Customer customer = _customerRepository.GetById(customerId);
customer.Email = newEmail;
_customerRepository.Save(customer);
Result result = _unitOfWork.SaveChanges();
if (result.IsFailure)
return result.Error;
return "OK";
}
Notice the additional SaveChanges method call. It might look excessive (since the controller already calls _userRepository.Save(user)), but it’s really not. Modifying the database and deciding whether to keep those modifications or roll them back are two separate responsibilities and should be attributed to different classes:
-
Repositories are responsible for data modifications
-
The unit of work — for transaction management
Not only do repositories and unit of work have different responsibilities, but they also have different lifespans. A unit of work lives during the whole business operation and is disposed of at the very end of it. A repository, on the other hand, is short-lived. You can dispose of a repository as soon as the call to the database is completed. As a result, repositories always work on top of the current unit of work. When connecting to the database, a repository enlists itself into the unit of work so that any data modifications made during that connection can later be rolled back by the unit of work.
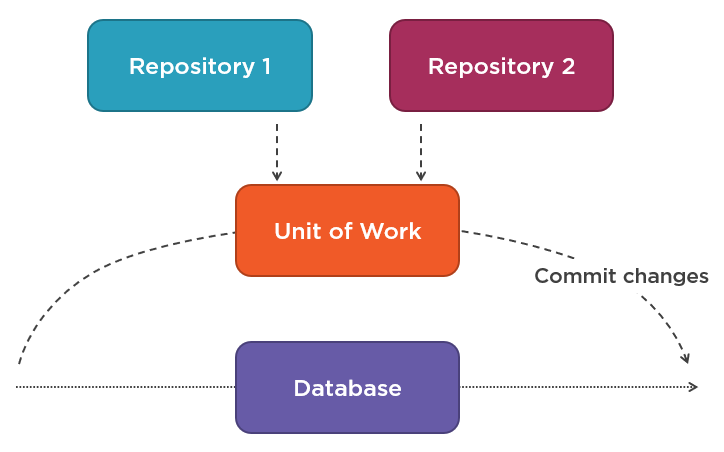
This is similar to how database transactions work. In fact, database transactions also implement the unit-of-work pattern.
Notice also that with the above implementation, all unexpected errors are re-thrown and ultimately converted into 500 responses. You don’t want to catch unexpected exceptions as if they are something you can deal with — those should still manifest themselves as internal server (500) errors.
Finally, you might have noticed that there are now essentially two email uniqueness checks. The first one is explicit:
Customer existingCustomer = _customerRepository.GetByEmail(newEmail);
if (existingCustomer != null && existingCustomer.Id != customerId)
return "Email is already taken";
And the second one is implicit:
Result result = _unitOfWork.SaveChanges();
if (result.IsFailure)
return result.Error;
You may remove the first one because it doesn’t add any value in terms of functionality — the second check fully covers the uniqueness requirement. But I still find it useful in terms of code readability because it makes that requirement explicit.
Summary
To handle unique constraint violations:
-
Catch uniqueness exceptions thrown by the database at the lowest level possible — in the
UnitOfWorkclass -
Convert them into
Result -
Use the
UnitOfWorkin the controller to explicitly commit pending changes and see if there are any uniqueness constraint violations
Subscribe
Comments
comments powered by Disqus







