Domain model purity and lazy loading
I’m continuing the topic of domain model purity. Last time, we talked about domain model purity in the context of getting the current date and time. Today, we’ll discuss it with regards to lazy loading.
Lazy loading
Before jumping into the topic of how lazy loading relates to domain model purity, let me give you a refresher on what lazy loading is.
Lazy loading is a design pattern where you defer initialization of an object until the time when it’s needed. The purpose of this pattern is to improve application performance.
The simplest example is probably the Singleton pattern (I’m ignoring concurrency issues for brevity):
public class MySingleton
{
private static MySingleton _instance;
public static MySingleton Instance
{
get
{
if (_instance == null)
{
_instance = new MySingleton();
}
return _instance;
}
}
}
Or, using .NET’s built-in Lazy class:
public class MySingleton
{
public static Lazy<MySingleton> Instance =
new Lazy<MySingleton>(() => new MySingleton());
}
The idea here is that if the creation of MySingleton is expensive, you may get performance benefits in scenarios which don’t use that class. Those scenarios will omit the creation of MySingleton altogether.
In this article, though, I’ll be talking about lazy loading in the context of ORMs, such as NHibernate and EF Core. The purpose of lazy loading in ORMs is the same: to postpone retrieving data from the database until as late a stage of the business operation as possible with the goal of omitting it altogether if the operation doesn’t require that data.
The use of lazy loading in ORMs got some flack in the past (and probably in the present too), primarily because of the N+1 problem (when the application does an excessive number of database roundtrips) and potential issues with out-of-context initialization. I disagree with this criticism. You can read more about my disagreement in this article.
Here are the main points I made in that article:
-
N+1 is prevalent in reads, but not in writes — In writes (operations that mutate the application’s state), you normally only need a portion of the aggregate’s data, so the number of database roundtrips isn’t that large. Also, you can easily mitigate the N+1 problem in reads by adhering to the CQRS pattern — by querying the database directly, using raw SQL and omitting the use of the ORM altogether.
-
In writes, lazy loading doesn’t damage performance that much (if at all) — With lazy loading, you query less data (only what the application needs), which balances out the increased number of database roundtrips. Also, the number of write operations and their frequency is small compared to the number of reads because your users read application data more often than they change it, and so the performance hit isn’t as noticeable.
At the same time, lazy loading provides huge simplicity benefits. I’d like to discuss those benefits in more detail. And now that I wrote about the DDD trilemma, I will also re-frame those benefits in terms of that trilemma.
Choosing the aggregate size
To understand the mechanism by which lazy loading provides such benefits, we need to step back and first discuss aggregates and their size.
Aggregates define transactional boundaries in your application: any modification done to an aggregate must remain consistent at all times. Aggregates are also the largest structures whose invariants are guaranteed to be enforced by the domain model. To enforce invariants that span more than one aggregate (such as user email uniqueness), you have to rely on out-of-process dependencies, such as your database, or implement custom roll-back procedures. The domain model alone can’t enforce such invariants.
In DDD, there’s a well-known problem of choosing a right aggregate size. Larger aggregates give you simplicity, but concede performance and throughput. Smaller aggregates provide the opposite set of pros and cons:
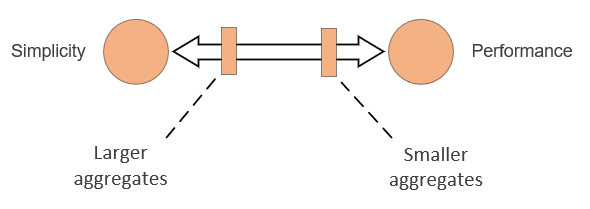
Larger aggregates make it easier to enforce application invariants because you can delegate that enforcement to the domain model itself, without relying on application services (controllers) or out-of-process dependencies. This is where the simplicity benefit comes from — with larger aggregates, it becomes easier to understand and maintain your application’s domain model.
The drawback of that approach is that you have to retrieve more data from the database with each business operation, even if that data isn’t required for the business operation at hand.
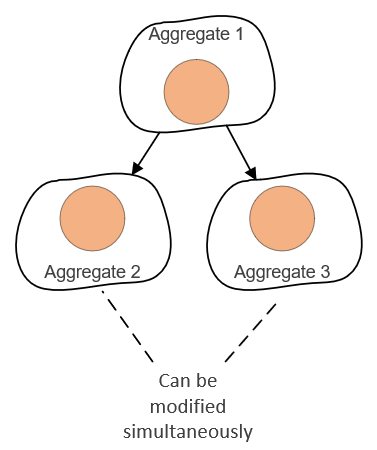
You are also damaging application throughput. With smaller aggregates, you can modify entities in them simultaneously with each other because their transactional boundaries don’t overlap:
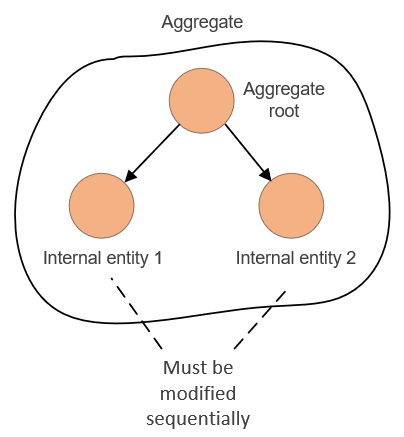
With larger aggregates, on the other hand, you have to modify those entities sequentially, and that modification must involve loading of the whole aggregate into memory:
Choosing the aggregate size: the DDD trilemma take
This trade-off between simplicity and performance can be re-framed using the DDD trilemma. Here’s the diagram that sums up that trilemma:
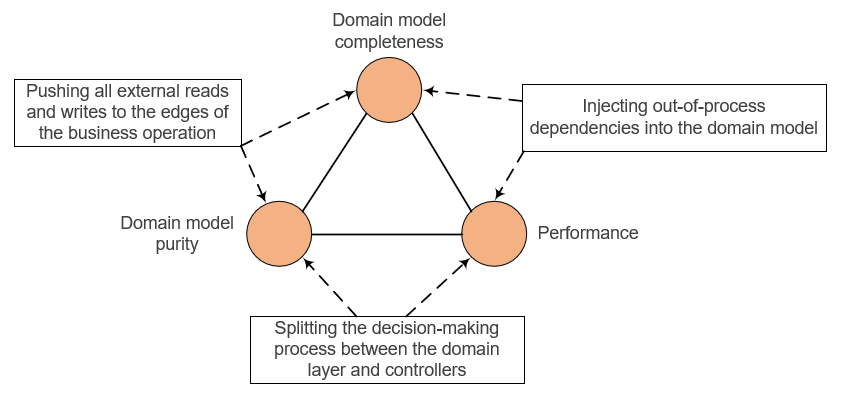
Both larger and smaller aggregates give you domain model purity, because neither of these two choices insist on referring to the database directly. The difference here is that:
-
With larger aggregates, you get domain model completeness at the expense of performance — Larger aggregates make it possible to keep the domain model encapsulated since you can enforce most of the application’s invariants within that domain model, without resorting to out-of-process dependencies.
-
With smaller aggregates, you make the opposite choice — You get performance but not domain model completeness/encapsulation.
Here’s this trade-off displayed on the same diagram:
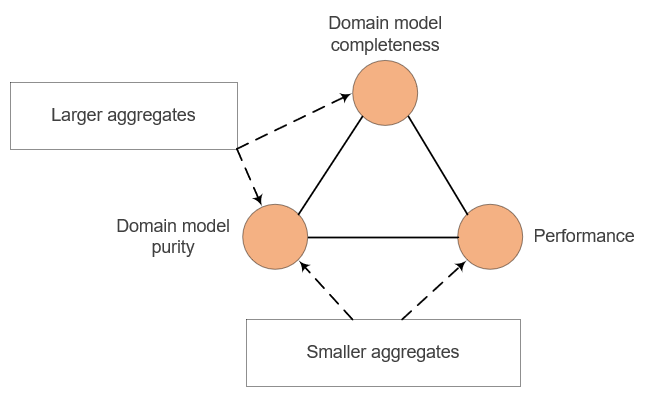
Notice that simplicity in the dilemma is the same as domain completeness in the trilemma. A complete domain model has no domain logic fragmentation, which makes it easier to understand and maintain that logic.
Also notice how neatly this performance-simplicity dilemma can be reduced to the more generic performance-completeness-purity trilemma.
Choosing the aggregate size: an example
Let’s take an example to illustrate the trade-off with the aggregate size. Let’s say that we have a User class, and we need to register all its login sessions in our application. A user relates to login sessions as 1-to-many (one user may have multiple sessions).
The system must register a new login session every time a user logs in, but only if it happens some configurable amount of time after the previous session. If not, the system should update the previous login session instead of creating a new one.
One way to implement this relationship is make the LoginSession class part of the User aggregate. This would allow us to put session-related logic directly into the User domain class:
public class UserController
{
public UserDto RegisterSession(int userId)
{
User user = _repository.GetById(userId);
user.RegisterSession(_dateTimeServer.Now);
_repository.Save(user);
}
}
public class User
{
private List<LoginSession> _loginSessions;
public IReadOnlyList<LoginSession> LoginSessions => _loginSessions.ToList();
public void RegisterSession(DateTime now)
{
LoginSession session = _loginSessions.Last();
if (session.HappenedRecently(now))
session.Update(now);
else
_loginSessions.Add(new LoginSession(this, now));
}
}
The downside here is that we can run into performance issues if the number of sessions becomes too large, because we have to load them all from the database even though we need only the last session.
The alternative implementation would be to put LoginSession into an aggregate of its own and handle the session-related logic in the controller, like this:
public class UserController
{
public void RegisterSession(int userId)
{
User user = _repository.GetById(userId);
LoginSession session = _sessionRepository.GetLast(user);
if (session.HappenedRecently(now))
{
session.Update(now);
_sessionRepository.Update(session);
}
else
{
LoginSession newSession = new LoginSession(user, now);
_sessionRepository.Add(newSession);
}
}
}
public class User
{
}
The performance with this implementation is better because we retrieve only the last session. But the decision-making process is now split between the controller and the domain layer (the controller gets the additional if statement). The domain model is no longer complete, nor it is fully encapsulated because the domain model is no longer responsible for all the application’s invariants.
I recommend choosing domain model completeness over performance, as long as performance impact is not noticeable or not critical for the application. You can always split the aggregate down the road if the performance becomes an issue.
Benefits of lazy loading
Alright, that was quite a preamble, but it’s required to understand the benefits of lazy loading, and I don’t think I wrote about aggregate sizes before on this blog (though I did talk about them in my DDD in Practice course).
So, what are those benefits?
Lazy loading allows you to work with larger aggregates without compromising application performance too much. In other words, you can mitigate the drawbacks of the large aggregates side of the trade-off (performance), while still enjoying its advantages (completeness, encapsulation, and simplicity).
The performance gains aren’t as noticeable when the aggregate contains just one internal entity, like in the example above where User is the aggregate root and LoginSession is the internal entity. But when there are multiple one-to-many and many-to-one relationships, you don’t want to load them all into memory in each business operation, that would be too cost-prohibitive. At the same time, you don’t necessarily want to reduce the aggregate size or delegate the decision-making process to the controllers either.
Lazy loading provides a good compromise where you load only the data required for the particular business operation, while still keeping the domain model rich and encapsulated. Lazy loading eliminates the need for additional hops between the domain model and controllers.
Of course, you get this benefit only when you use an ORM that enables lazy loading out-of-the-box. Don’t try to implement custom lazy loading. Performance gains will not make up for the huge complexity overhead.
Domain model purity
But doesn’t lazy loading affect domain model purity? After all, in this example:
// User class
public void RegisterSession(DateTime now)
{
LoginSession session = _loginSessions.Last();
if (session.HappenedRecently(now))
session.Update(now);
else
_loginSessions.Add(new LoginSession(this, now));
}
the _loginSessions.Last() expression would result in a database call if the user’s sessions are not yet loaded into memory, even though, technically, the User class doesn’t refer to out-of-process dependencies here.
To answer the question of whether or not lazy loading violates domain model purity, we need to discuss what this purity means. I know, I already brought up the definition of domain model purity in the previous articles (twice), but to tackle this one, we really need a precise definition.
So here it is. A pure domain model has the following attributes:
-
Its domain classes don’t explicitly refer to out-of-process dependencies or classes from the application services layer. In other words, domain classes should only depend on other domain classes or the framework’s built-in primitive types.
-
All inputs to the domain model are referentially transparent, except for calls to the domain classes themselves. Referential transparency means that you can replace a method call or an expression with the output of that method call or expression, and it will not change the code’s behavior.
-
All side effects are limited to the domain model — Domain classes should only modify themselves, not out-of-process dependencies or classes from the application services layer. This attribute flows from the first attribute but is still worth stating explicitly.
This attribute, along with the exception in the second attribute ("expect for calls to the domain classes themselves") is what differentiates a pure domain model from pure code in a functional programming sense. In functional programming, a pure code is always referentially transparent (which also means it works with immutable data only and doesn’t incur side effects), while in DDD, the notion of purity isn’t as strict.
Notice that the first attribute allows for the use of the framework’s built-in primitive types in the domain model. The line between primitive and non-primitive types is blurry at times, but you can think of it the same way as of the difference between POCO and non-POCO classes. When it comes to .NET, the use of string, int, and Func is probably fine, while Component or EventLog is probably not.
Now that we have the definition of domain model purity, let’s take a closer look at some examples, including those I brought up in the previous articles of this series.
IUserRepository interface
An IUserRepository interface is an explicit reference to an out-of-process dependency (the application database) and goes against the first attribute. Hence, a domain model using such an interface is not pure.
As a reminder, I brought up this example in the first article as a potential solution to domain logic fragmentation when changing the user email and checking for that email uniqueness:
// User class
public Result ChangeEmail(string newEmail, IUserRepository repository)
Func<string, bool> delegate
What about the following code?
// User class
public Result ChangeEmail(string newEmail, Func<string, bool> isEmailUnique)
The use of Func doesn’t violate the first attribute. You can’t infer a database call here because this delegate may very well refer to in-memory data. I also wouldn’t consider Func a non-POCO class because it’s an inherent part of .NET Framework.
However, this implementation doesn’t meet the second attribute — the delegate is not referentially transparent. You can’t replace this call:
bool isUnique = isEmailUnique();
with its outcome, like this:
bool isUnique = false;
At least not without changing the program’s behavior. Therefore, this implementation is not pure either.
Func<string, Task<bool>> delegate
What about a variation of the previous solution that uses asynchronous database calls?
// User class
public async Task<Result> ChangeEmail(string newEmail, Func<string, Task<bool>> isEmailUnique)
{
bool isUnique = await isEmailUnique();
/* ... */
}
Of course, it still violates attribute #2, but in addition to that, it now also violates attribute #1. The only reason why you are using Task's here is to facilitate a database call — to make it asynchronous. You don’t need asynchrony with in-memory calls. Therefore, this is an explicit reference to an out-of-process dependency.
DateTime.Now property
Similar to the Func<string, bool> isEmailUnique delegate, calls to the DateTime.Now property make your domain model impure because these calls are not referentially transparent — they return different results with each invocation.
Notice, though, that the use of DateTime.Now doesn’t go against the first attribute — it’s not a reference to an out-of-process dependency, nor it is a reference to a non-POCO class.
IQueryable interface
The use of the IQueryable interface also makes your domain model impure because it violates attribute #1. The only reason why you would possibly want to use IQueryable instead of IEnumerable is to do database calls. This is an explicit reference to an out-of-process dependency.
Lazy loading and domain model purity
Finally, let’s go back to our example where the LoginSessions collection is loaded lazily by the ORM:
public class User
{
private List<LoginSession> _loginSessions;
public virtual IReadOnlyList<LoginSession> LoginSessions => _loginSessions.ToList();
public virtual void RegisterSession(DateTime now)
{
LoginSession session = _loginSessions.Last();
if (session.HappenedRecently(now))
session.Update(now);
else
_loginSessions.Add(new LoginSession(this, now));
}
}
Is this implementation pure or not? It is pure.
First of all, there’s no references to out-of-process dependencies. _loginSessions.Last() is a call to the private field and we can’t infer from this code whether it makes a database call.
What about the second attribute? The _loginSessions.Last() call is an input to the domain model. It is not referentially transparent, but since this call refers to the data in the domain class itself, it falls into the exception portion of the rule: all inputs to the domain model are referentially transparent, expect for calls to the domain classes themselves.
The same goes for the third attribute. The _loginSessions.Add(…) call is not referentially transparent either (side effects are not referentially transparent by definition), but this modification is contained within the domain layer and doesn’t cross the domain layer’s boundary. The class changes its own state; it doesn’t persist that state to the database.
Look at this from another perspective. A base class is not responsible for what its subclasses are doing. As long as this base class doesn’t explicitly rely on its subclasses to communicate with the database (that is, doesn’t introduce abstract methods with Task's in their signature), it remains pure.
This is exactly the case in our example. The ORM creates proxy classes that inherit from User at runtime, but the User itself is oblivious to that fact. We can strip the domain model of the ORM and the database, and it will not affect that domain model’s behavior.
On the contrary, with this implementation:
// User class
public Result ChangeEmail(string newEmail, Func<string, bool> isEmailUnique)
{
bool isUnique = isEmailUnique();
/* ... */
}
we rely on some underlying magic with regards to the email uniqueness verification. The same is true of DateTime.Now: it pretends to be a simple getter property (which is handy), but it is not — it’s not referentially transparent.
Explicit lazy loading
In EF Core, there’s a relatively new feature that allows you to lazy load relationships explicitly, without runtime proxies.
It works something like this:
public class User
{
private ILazyLoader _lazyLoader;
private List<LoginSession> _loginSessions;
public IReadOnlyList<LoginSession> LoginSessions => _lazyLoader.Load(this, ref _loginSessions);
public User(ILazyLoader lazyLoader)
{
_lazyLoader = lazyLoader;
}
public void RegisterSession(DateTime now)
{
_lazyLoader.Load(this, ref _loginSessions);
LoginSession session = _loginSessions.Last();
if (session.HappenedRecently(now))
session.Update(now);
else
_loginSessions.Add(new LoginSession(this, now));
}
}
Unlike the version with runtime proxies, this one is not pure. It violates both the first and the second attributes:
-
The
Usernow depends onILazyLoader, which is not a POCO class. -
The call to
_lazyLoader.Load(…)is not referentially transparent.
Summary
-
Choosing an aggregate size is a trade-off between simplicity and performance.
-
Larger aggregates result in simpler solutions (which itself is a result of enforcing all the application invariants within the domain model itself).
-
Smaller aggregates result in better performance and throughput, because you query and lock less data with each business operation.
-
-
The performance-simplicity dilemma can be reduced to the more generic performance-completeness-purity trilemma. Simplicity in the dilemma == completeness in the trilemma.
-
Lazy loading allows you to work with larger aggregates without compromising application performance.
-
Lazy loading with runtime proxies doesn’t make the domain model impure. Explicit lazy loading does.
Other articles in the series
-
Domain model purity and lazy loading (this article)
Related
Subscribe
Comments
comments powered by Disqus







