Immutable architecture
The topic of immutable architecture described here is part of my Applying Functional Principles in C# Pluralsight course.
In this post, I’d like to show a common approach to introducing immutability to your code base on an architectural level.
Immutability, State, and Side Effects
Before we start, let’s take a minute to define the terms. Most likely, you have already encountered them but I want to make sure we are on the same page here.
First of all, the term "Immutability" applied to a data structure such as a class means that objects of this class cannot change during their lifetime. There are several types of immutability with their own nuances, but they are not essential for us. For the most part, we can say that a class is either mutable, meaning that its instances can change in some way or another, or immutable, meaning that once we create an instance of that class, we cannot modify it later on.
Another important term is "State". It indicates data that changes over time. It’s important to understand that state is not just data that comprises a class, state is a subset of this data that changes during its lifespan. An immutable class doesn’t have any state in that sense, only mutable classes do.
A side effect is a change that is made to some state. Usually, we say that an operation leaves a side effect if it mutates an instance of a class, updates a file on the disk or saves some data into the database.
Here’s an example that will help you bind all three concepts together:
public class UserProfile // Mutable, contains state
{
private User _user;
private string _address;
public void UpdateUser(int userId, string name) // Leaves a side effect
{
_user = new User(userId, name);
}
}
public class User // Immutable, doesn't contain state
{
public int Id { get; }
public string Name { get; }
public User(int id, string name)
{
Id = id;
Name = name;
}
}
The User class is immutable: all its properties are defined as read-only. Because of that, the only way for the UpdateUser method to update the user field is to create a new user instance and replace the old one with it. The User class itself doesn’t contain state whereas the UserProfile class does. We can say that the UpdateUser method leaves a side effect by changing the object’s state.
Immutable architecture
Methods with side effects make your code harder to reason about because of the dishonesty they bring to it. However, even if you try to impose immutability as much as possible, you cannot avoid them completely. Programming a system which doesn’t change would be impractical. After all, side effects is what software programs are supposed to do: they perform some calculations and they change their state in one way or another.
So how to deal with side effects? One of the techniques that help us to do that is separating the application’s domain logic from the logic of applying the side effects to the system’s state.
Let’s elaborate on that. It often happens that while processing a business transaction our code mutates some data several times from the point when the request comes into the application to the point where it is processed completely. This is a quite common pattern, especially in the world of object-oriented programming languages. What we can do instead is we can isolate the code that generates some artefacts from the code that uses them to change the system’s state:
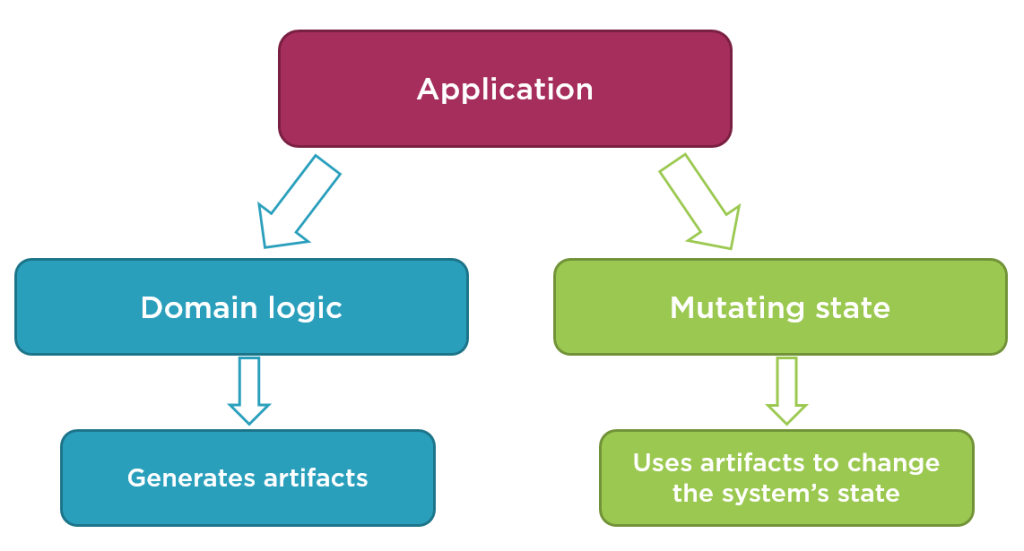
The first portion then can be made immutable, we can free it up from any side effects.
Such approach gives us two benefits:
-
We simplify the domain logic as all code in it can be written in a functional way, using mathematical functions.
-
Such logic becomes extremely easy to test. The results of all operations are clearly defined in the methods' outputs, so unit testing boils down to supplying a method an input and verifying its output.
Such architecture is an essential part of how most code bases written in functional languages operate. In the vast majority of cases, you have an immutable core which accepts an input and which contains all the logic for processing that input. This core is written using mathematical functions and for each request returns corresponding artefacts without mutating the system’s state:
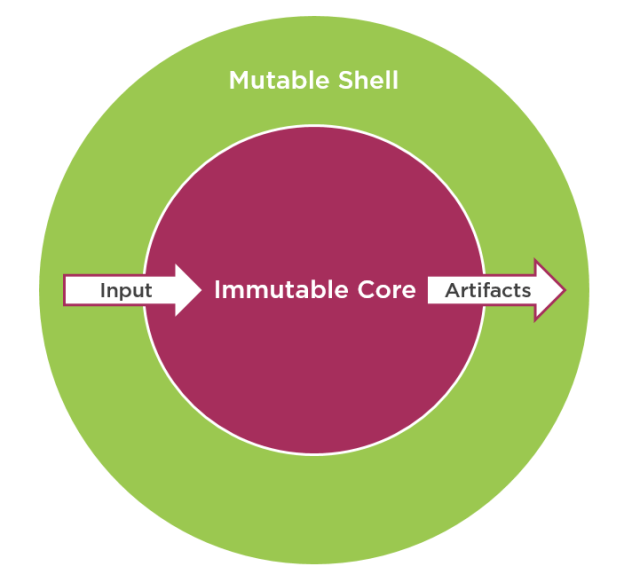
And you also have a thin mutable shell which provides the input for the immutable core and which accepts the resulting artefacts and then saves them to the database. This shell comes into play when the core finishes working; it doesn’t contain any business logic.
Overall, the mutable shell should be made as dumb as possible. Ideally, try to bring it to the cyclomatic complexity of 1. In other words, try not to introduce any conditional operators (if statements) in it.
This approach also makes it natural to compose different sub-systems together:
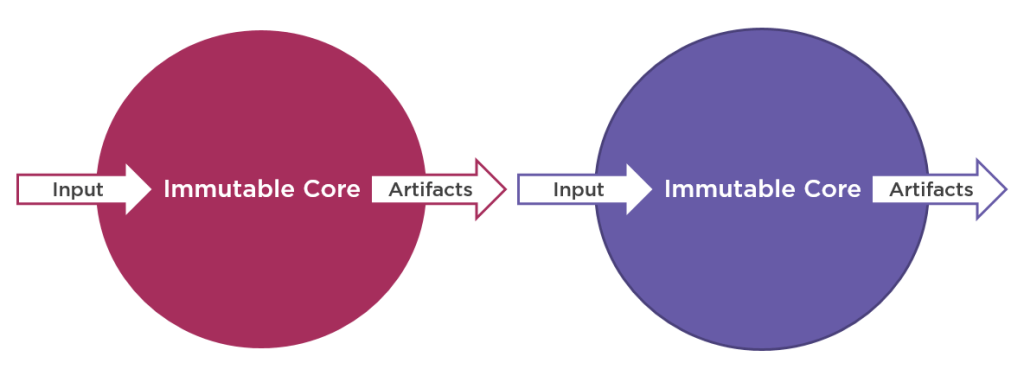
We can take the core part and attach another component to it easily, due to its being immutable. Unit tests essentially act as such a component: instead of saving the artefacts to the database, unit tests verify them and then just throw away.
Immutable architecture example
An example here can be an audit manager class that keeps track of all visitors of some organization. It uses flat text files as an underlying storage:
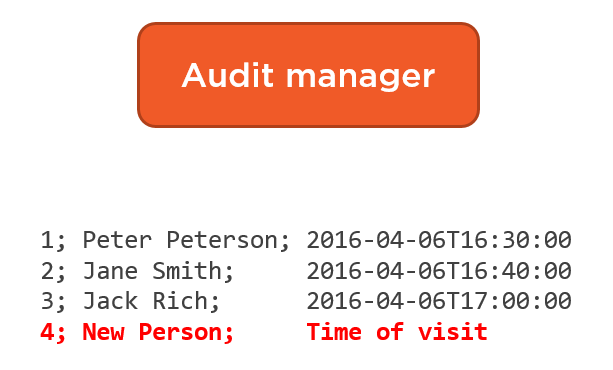
The class is able to add new records to the log file, and remove information about the existing ones. It should also respect the maximum number of records a single file can contain and create a new one in case that limit is exceeded.
A straightforward implementation would look like this. Two methods which take some parameters and read and mutate the files directly:
public class AuditManager
{
private readonly int _maxEntriesPerFile;
public AuditManager(int maxEntriesPerFile)
{
_maxEntriesPerFile = maxEntriesPerFile;
}
public void AddRecord(string currentFile, string visitorName, DateTime timeOfVisit)
{
string[] lines = File.ReadAllLines(currentFile);
if (lines.Length < _maxEntriesPerFile)
{
// Add a record to the existing log file
}
else
{
// Create a new log file
}
}
public void RemoveMentionsAbout(string visitorName, string directoryName)
{
foreach (string fileName in Directory.GetFiles(directoryName))
{
// Remove records about the visitor from all files in the directory
}
}
}
Immutable versions of these methods, on the other hand, should clearly define their inputs and outputs:
public class AuditManager
{
public FileActionAddRecord(
FileContent currentFile, string visitorName, DateTime timeOfVisit)
{
// Return a new FileAction with the Update or Create action type
}
public IReadOnlyList<FileAction> RemoveMentionsAbout(
string visitorName, FileContent[] directoryFiles)
{
// Exercise each of the directory files and return a collection
// of actions that needs to be performed
}
}
public struct FileAction
{
public readonly string FileName;
public readonly string[] Content;
public readonly ActionType Type;
}
public enum ActionType
{
Create,
Update,
Delete
}
public struct FileContent
{
public readonly string FileName;
public readonly string[] Content;
}
Here, the FileContent class fully encodes all information that our domain logic needs in order to operate properly. FileAction, on the other hand, contains the full set of instructions regarding what to do with files in the file system. They instruct the outside world about the actions that need to be taken.
AuditManager doesn’t perform those actions by itself, we need to introduce a Persister class for that purpose:
public class Persister
{
public FileContentReadFile(string fileName)
{
return new FileContent(fileName, File.ReadAllLines(fileName));
}
public void ApplyChange(FileAction action)
{
switch (action.Type)
{
caseActionType.Create:
caseActionType.Update:
File.WriteAllLines(action.FileName, action.Content);
return ;
caseActionType.Delete:
File.Delete(action.FileName);
return ;
default:
throw new InvalidOperationException();
}
}
}
Note that Persister is very simple, it just reads data from the file system and writes the changes back to it.
Finally, an application service should glue the two together:
public class ApplicationService
{
private readonly string _directoryName;
private readonly AuditManager_auditManager;
private readonly Persister_persister;
public ApplicationService(string directoryName)
{
_directoryName = directoryName;
_auditManager = new AuditManager(10);
_persister = new Persister();
}
public void AddRecord(string visitorName, DateTime timeOfVisit)
{
FileInfo fileInfo = new DirectoryInfo(_directoryName)
.GetFiles()
.OrderByDescending(x => x.LastWriteTime)
.First();
FileContent file = _persister.ReadFile(fileInfo.Name);
FileAction action = _auditManager.AddRecord(file, visitorName, timeOfVisit);
_persister.ApplyChange(action);
}
}
This immutable version contains two pieces: an immutable core which holds all business rules and a mutable shell which acts upon the data the core generates. Such separation helps us get rid of side effects in the audit manager class completely. All methods in that class are mathematical functions, with clearly defined input and output. Persister works as a provider of input data for the manager and also as a consumer for the data it generates. The Application Service glues them together.
There are two best practices when it comes to creating an immutable architecture. First, make sure you separate the code that mutates the application’s state from the code that contains business logic. Make the mutable shell as dumb as possible. And second, apply those side effects as close to the end of a business transaction as you can.
For the most part, that is the way functional languages cope with side effects. The biggest and most important part of the system - its domain logic - is usually made immutable while the code that incurs side effects is simple and straightforward.
You can find the full source code of this example on GitHub. Here are quick links to the specific parts of it:
Subscribe
Comments
comments powered by Disqus







