CQRS vs Specification pattern
This is an article about how two DDD patterns contradict each other.
CQRS vs Specification pattern
These two Domain-Driven Design patterns - CQRS and the Specification pattern - contradict each other. And not just lightly, they are at odds in the most fundamental way.
Let’s first recap what they stand for. The CQRS pattern is about splitting a single unified model into two: one for reads and the other one for writes. This seemingly simple exercise leads to quite significant benefits, the most important of which is simplicity.
The command side and the query side of your application have drastically different needs. Introducing a separate model for each of these sides is a natural way to make this difference explicit. This, in turn, allows you to offload a lot of complexity from your code base. With such a separation, you don’t have to worry about handling two completely different use cases with the same code. You can focus on each of them independently and come up with a solution that makes the most sense in each particular case. You can view it as the single responsibility principle applied at the architectural level. In the end, you get two models, each of which does only one thing, and does it well.
I published an online course about CQRS recently, check it out here: CQRS in Practice.
The Specification pattern is about encapsulating a piece of domain knowledge into a single unit - called specification - and then reusing in different scenarios. There are three such scenarios: data retrieval, in-memory validation, and creation of a new object ("Construction-to-order" on the figure below).
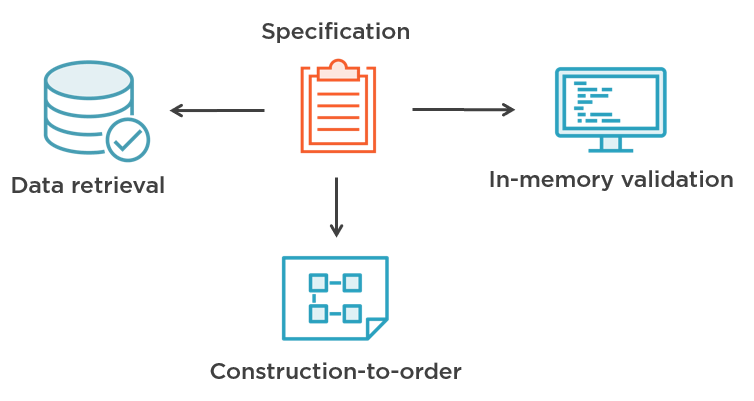
The scenario of creating a new object using a specification is quite rare and not relevant here so I’ll omit it. Data retrieval is about fetching data from the database - finding records that match the specification. And in-memory validation is when you check that some object complies with the criteria described by the specification.
This is useful because it allows you to avoid the domain knowledge duplication. The same specification class can be used for both validation of the incoming data and filtration of the data from the database when you show it to the user.
At the same time, the CQRS pattern proposes the separation of the two:
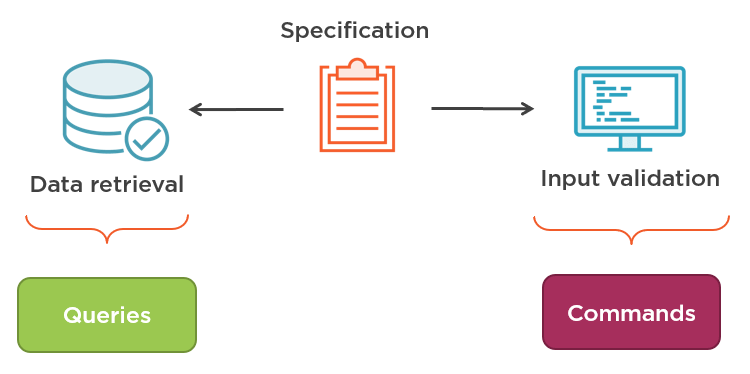
Validation belongs in the command side. It precedes data mutation as you normally validate the incoming data before you change something. Whereas data retrieval belongs in the read side. It’s what the client queries to see what data there is in your system.
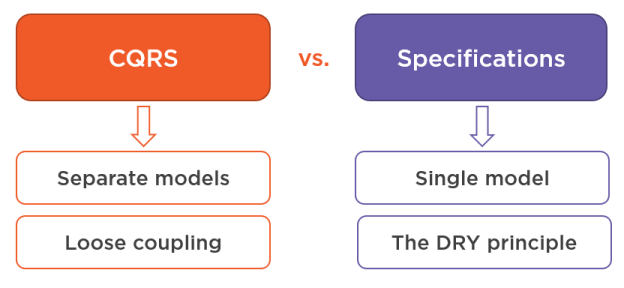
And so there’s a clear contradiction here. On the one hand, the Specification pattern advocates for having a single domain model for these two concerns. On the other - CQRS advocates for splitting the domain model into two and dealing with those concerns separately.
What you can see here is the classic example of the contradiction between the DRY principle, which stands for don’t repeat yourself, and the principle of loose coupling. Both of these principles are foundational, they are at the core of most software development practices you employ at your day-to-day work.
So, which one should you prefer?
The guideline here is this: loose coupling wins in the vast majority of cases.
When choosing between high coupling and domain knowledge duplication, the latter is the lesser evil. When you duplicate the domain knowledge, it’s not very convenient but it’s not that bad when you compare it to the alternative.
And the alternative - the high coupling - can be devastating. With it, you are pretty much stuck with your hands tied behind your back. Your options are severely limited as you have to take into account not only the requirements posed by the component you develop but also by all other components that depend on this implementation.
In the scenario with the input validation and data retrieval, this manifests itself in inability to efficiently query data from the database. You can’t employ native querying mechanism of the underlying data storage and have to fall back to the lowest common denominator. That is, come up with a solution that handles neither of the two scenarios well.
Unfortunately, the Specification pattern works only in simple cases, where you don’t need sophisticated querying logic. And in such cases, it may be fine to use this pattern.
However, it large systems, you should almost always choose the loose coupling over preventing the domain knowledge duplication between the reads and writes. The freedom to choose the most appropriate solution for the problem at hand trumps the DRY principle.
Interestingly enough, I have an online course about the Specification pattern too, here it is: Specification Pattern in C#. It’s a short one - just north of 1 hour - and its shortness it partly due to this fact that there’s not much use for it in the real-world projects. I didn’t mention this when I was writing this course (despite being fully aware of this contradiction at the time of recording) and I feel slightly bad about it now. But hey, better late than never. And it’s still an interesting topic to learn, even if you don’t find a use for this pattern in your own projects.
Summary
So, here you go, the great contradiction between the CQRS and Specification patterns is now revealed.
-
CQRS is about splitting reads and writes into separate models.
-
Specification pattern is about reusing bits of domain logic in reads and writes.
-
CQRS represents the overarching principle of loose coupling.
-
Specification pattern represents the overarching principle of DRY (Don’t Repeat Yourself, avoidance of domain knowledge duplication).
-
Loose coupling trumps DRY in the vast majority of cases, except the simplest ones.
Related
Subscribe
Comments
comments powered by Disqus







