What is functional programming?
The topic of functional programming described here is a part of my Applying Functional Principles in C# Pluralsight course.
In this article, I’ll try to answer the question: what is functional programming?
Functional programming
So, what is functional programming? This term arises quite often and every author writing about it gives their own explanation. I’m no exception. In my opinion, the simplest and at the same time precise definition is the following: functional programming is programming with mathematical functions.
Mathematical functions are not methods in a programming sense. Although we sometimes use the words "method" and "function" as synonyms, they aren’t the same concepts from the functional programming point of view. The best way to think of a mathematical function is as of a pipe that transforms any value we pass it into another value:
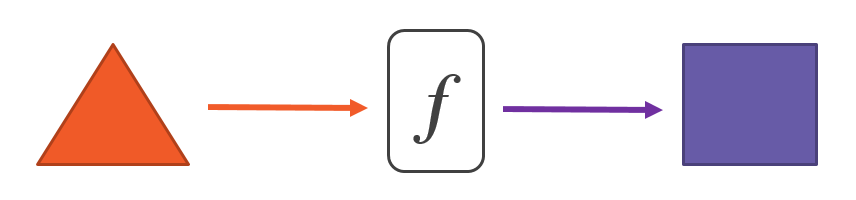
And that’s basically it. A mathematical function doesn’t leave any marks in the outside world about its existence. It does only one thing: finds a corresponding object for each object we feed it.
In order for a method to become a mathematical function, it must fit two requirements. First of all, it should be referentially transparent. A referentially transparent function always produces the same result as long as you supply it the same arguments. It means that such function should operate only the values we pass in, it shouldn’t refer to the global state.
Here’s an example:
public long TicksElapsedFrom(int year)
{
DateTime now = DateTime.Now;
DateTime then = new DateTime(year, 1, 1);
return (now - then).Ticks;
}
This method is not referentially transparent because it returns different results even if we pass it the same year. The reason here is that it refers to the global DatetTime.Now property.
A referentially transparent alternative for this method would be:
public long TicksElapsedFrom(int year, DateTime now)
{
DateTime then = new DateTime(year, 1, 1);
return (now - then).Ticks;
}
This version operates only the parameters passed in.
Secondly, the signature of a mathematical function must convey all information about the possible input values it accepts and the possible outcome it may produce. I call this trait method signature honesty.
Look at this code sample:
public int Divide(int x, int y)
{
return x / y;
}
The Divide method, despite being referentially transparent, is not a mathematical function. Its signature states that it accepts any two integers and returns another integer. But what happens if we pass it 1 and 0 as input parameters?

Instead of returning an integer as we’d expect, it will throw a Divide By Zero exception. It means that the method’s signature doesn’t convey enough information about the result of the operation. It deceives the caller by pretending that it can handle any two parameters of the integer type whereas in practice it has a special case which cannot be processed.
In order to convert the method into a mathematical function, we need to change the type of the "y" parameter, like this:
public static int Divide(int x, NonZeroInteger y)
{
return x / y.Value;
}
Here, NonZeroInteger is a custom type which can contain any integer except zero. This way, we’ve made the method honest as it now doesn’t behave unexpectedly for any values from its input range. Another option is to change its returning type:
public static int ? Divide(int x, int y)
{
if (y == 0)
return null;
return x / y;
}
This version is also honest as it now doesn’t guarantee that it will return an integer for any possible combination of input values.
Despite the simplicity of the functional programming definition, it entails a lot of practices that might seem novel to many programmers. Let’s see what they are.
Side effects
The first such practice is avoiding side effects as much as possible by employing immutability all over your code base. This technique is important because the act of mutating state contradicts the functional principles.
The signature of a method with a side effect doesn’t communicate enough information about what the actual result of the operation is, and that hinders our ability to reason about it. In order to validate your assumptions regarding the code you are writing, not only do you have to look at the method’s signature itself, but you also need to fall down to its implementation details and see if this method leaves any side effects that you didn’t expect:
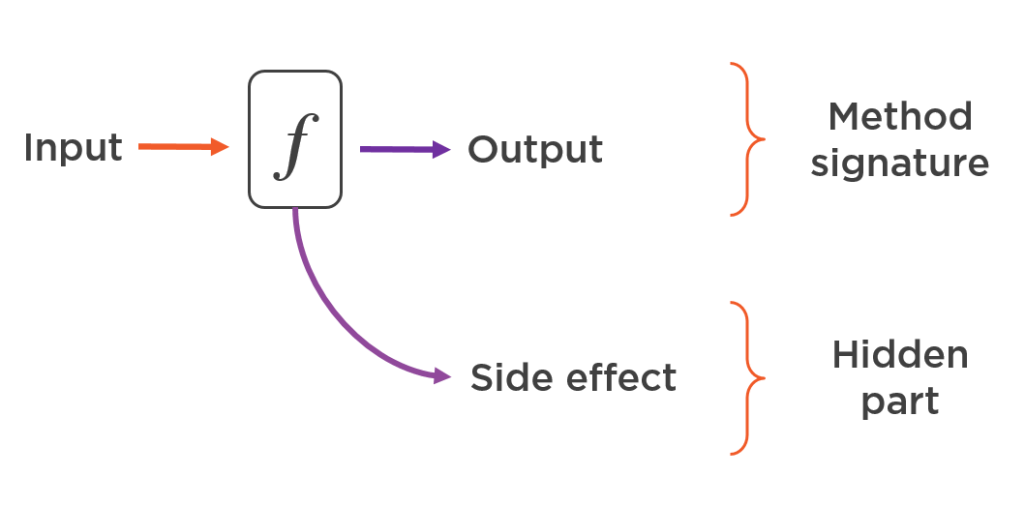
Overall, code with data structures that change over time is harder to debug and is more error-prone. It brings even more problems in multi-threaded applications where you can have all sorts of nasty race conditions.
When you operate immutable data only, you force yourself to reveal hidden side effects by stating them in the method’s signature and thus making it honest. This makes the code more readable because you don’t have to fall down to the methods' implementation details in order to reason about the program flow. With immutable classes, you can just look at the signature of a method and get a good understanding of what is going on right away, without too much effort.
Exceptions
Exceptions is another source of dishonesty for your code base. Methods that employ exceptions to control the program flow are not mathematical functions because, just like side effects, exceptions hide the actual outcome of the operation the method performs.
Moreover, exceptions have a goto semantics meaning that they allow you to easily jump from any point of your program to a catch block. In fact, exceptions perform even worse because the goto statement doesn’t allow for jumping outside a particular method, whereas with exceptions you can cross multiple layers in your code base with ease.
Primitive Obsession
While side effects and exceptions make your methods dishonest about their outcomes, primitive obsession deceives the reader about the methods' input values. Here’s an example:
public class User
{
public string Email { get; private set; }
public User(string email)
{
if (email.Length > 256)
throw new ArgumentException("Email is too long");
if (!email.Contains("@"))
throw new ArgumentException("Email is invalid");
Email = email;
}
}
public class UserFactory
{
public User CreateUser(string email)
{
return new User(email);
}
}
What the signature of the CreateUser method tells us? It says that for any input string, it returns a User instance. In practice, however, it accepts only strings that are formatted in a particular way and throws exceptions if they are not. Therefore, this method is dishonest as it doesn’t convey enough information about the kinds of strings it works with.
This is essentially the same problem you saw with the Divide method:
public int Divide(int x, int y)
{
return x / y;
}
The type of the parameter for email, as well as the type of the parameter for "y", is more coarse-grained than the actual concept they represent. The number of states an instance of the string type can be in exceeds the number of valid states for a properly formatted email. This disparity results in deception for the developer who uses such a method. It makes the programmer think that the method works with primitive strings whereas, in the reality, this string represents a domain concept with its own invariants.
Just as with the Divide method, the dishonesty can be fixed by introducing a separate Email class and using it in place of the string.
Nulls
Another practice in this list is avoiding nulls. It turns out that the use of nulls makes your code dishonest as the signature of the methods using them doesn’t tell all information about the possible outcome the corresponding operation may have.
In fact, in C#, all reference types act as a container for two kinds of values. One of them is an instance of the declared type, and the other one is null. And there’s no way to distinguish between the two as this functionality is baked into the language itself. You have to always keep in mind that when you declare a variable of a reference type, what you actually do is you essentially declare a variable of a custom two-fold type which can contain either a null reference or an actual instance:
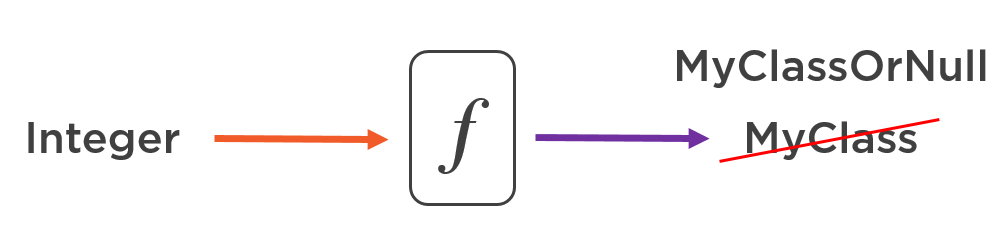
In some cases, it’s exactly the thing you need but sometimes, you want to just return MyClass, without a possibility for it to turn into null. The problem here is that there’s no way to do that in C#. There’s no way to distinguish between nullable and non-nullable reference types. It means that methods with reference types in their signature are inherently dishonest.
This issue can be fixed by introducing the Maybe type and an agreement across the team that whenever you define a nullable variable, you use the Maybe type to do that.
Why functional programming?
An important question that comes to mind when you read about functional programming is: why bother about it in the first place?
To answer it, we need to refer to the pain points that we as an industry have at the moment. One of the biggest problems that come into play in enterprise software development is complexity. The complexity of the code base we are working on is the single most important factor that affects such things as speed of development, the number of bugs and the ability to quickly adjust to ever-changing market needs.
There is only so much of complexity we can deal with at a time. If the project’s code base overwhelms this limit, it becomes really hard, and at some point even impossible, to change anything in the software without introducing some unexpected side effects.
Applying functional programming principles helps reduce code complexity. It turns out that programming with mathematical functions makes our job a lot less complicated. Because of the two traits they possess - method signature honesty and referential transparency - we are able to understand and reason about such code much easier.
Every method in our code base - if written as a mathematical function - can be considered in isolation from others. When we are sure that our methods don’t affect the global state or blow up with an exception, we can treat them as building blocks and compose in any way we want. This, in turn, unlocks great opportunities for building complex functionality which itself is not much harder to create than the parts it consists of.
With honest method signatures, we don’t have to fall down to the method’s implementation details or refer to the documentation to see if there’s something else we need to consider before using it. The signature itself tells us what can happen after we call such method. Unit testing also becomes much easier. It comes down to a couple of lines where you just provide an input value and check that the result is the one you excepted. No need to create complex test doubles, such as mocks and maintain them later on.
Summary
Functional programming is programming with mathematical functions. Most methods in the C# language can potentially be converted into mathematical functions. To do this, we need to make their signatures honest in a sense that they should fully convey all possible inputs and outcomes and we also need to make sure the method operates only the values we pass in, nothing else.
Practices that help convert C# methods into mathematical functions are:
-
Immutability
-
Avoiding exceptions to control the program flow
-
Getting rid of primitive obsession
-
Making nulls explicit
I go into the topic of functional programming in much more detail in my Pluralsight course Applying Functional Principles in C#, so be sure to check it out.
Related articles:
- ← Applying Functional Principles in C# Pluralsight course
- Defensive programming: the good, the bad and the ugly →
Subscribe
Comments
comments powered by Disqus







