State vs migration-driven database delivery
The topic described in this article is a part of my Database Delivery Best Practices Pluralsight course
In the previous post, I wrote about the database versioning best practices. I’ve got a lot of feedback on that topic. One of the responses stated that the article was (admittedly) one-sided as it didn’t cover the other widely spread approach to managing the database delivery process. I decided to fill that gap and provide my own comparison of the two. This article is about the state versus migration-driven database delivery.
State-driven database delivery
The state-driven approach was initially introduced by such vendors as Redgate and later popularized by Microsoft when they shipped Visual Studio database project. The idea is pretty simple and yet very appealing: all we need to do is we need to maintain a snapshot of our database structure. A compare tool then will auto-generate the scripts required to upgrade any existing database to mimic the etalon.
The whole upgrade process looks like this:
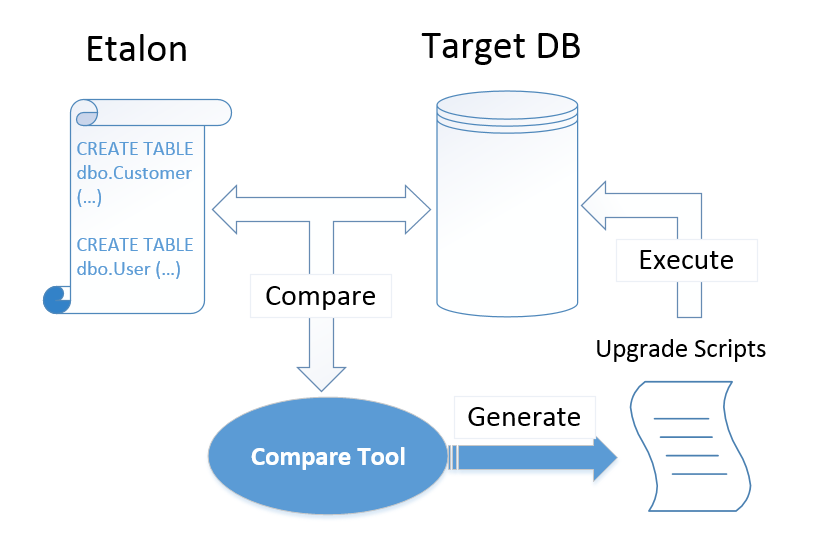
It doesn’t matter how many differences are there between the database being upgraded and the snapshot database. The target DB can be empty or it can be one of the previous versions of the snapshot DB, the scripts generated will do everything needed to get it in sync with the snapshot DB.
Essentially, the tool generating the upgrade scripts does all the hard work. The intention behind this approach is to free us, developers, from that work and make our life easier.
Migration-driven database delivery
The migration-driven approach takes another side. Instead of having a single etalon, it implies creating a bunch of migrations that transition a database from one version to another:
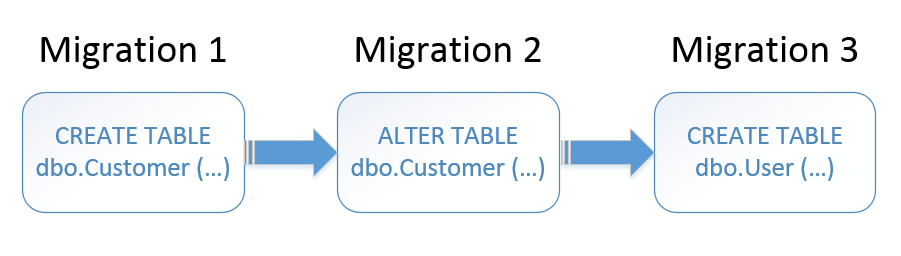
Those migrations might be represented in different ways. Plain SQL scripts is the most popular choice, but they could also be written in some DSL-like language:
[Migration(1)]
public class CreateUserTable : Migration
{
public override void Up()
{
Create.Table("Users");
}
public override void Down()
{
Delete.Table("Users");
}
}
Regardless of how the migrations are represented, they should be able to be unambiguously translated into upgrade scripts which then can be executed against the database. This means that, by and large, we have to code the migrations manually.
State vs migration-driven database delivery: comparison
The two approaches have different implications to the database delivery process. Those differences can be boiled down to two points: resolving merge conflicts and handling data migrations. Let’s elaborate on that.
Merge conflicts arise when two or more programmers work on the same piece of a database. The state-driven approach allows us to handle them in the easiest way possible. As the whole database is represented as an SQL script, the merge process is pretty straightforward:
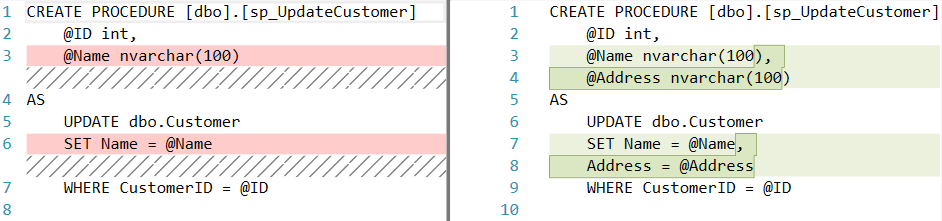
At the same time, if you deal with a set of migration scripts, it might be extremely tedious to handle conflicts in them. This is mainly related to the work with stored procedures and database functions as they are prone to the "last migration wins" problem the most.
With migrations, you have to carefully proof-read every line in the conflicting changes to make sure the resulting migrations take all of them into account.
Data migration is the process of changing the shape of existing data so that it conforms to the new database schema. An example of such migration would be the process of splitting a name column up into two fields: the first name and the last name.
There is no easy way to implement this change with state-driven database delivery. The compare tools are awful when it comes to managing not only a database schema but also its data. It’s no wonder. While the DB schema is objective, meaning that there is the only way to interpret it, the data inside is context-dependent. That means the tool can’t make reliable assumptions about the data in order to generate the upgrade scripts, and we have to deal with it by ourselves anyway.
Such duality is a huge problem in the world of state-driven database delivery. Eventually, we find ourselves in a position where we have auto-generated scripts for DB schema on one hand, and manually crafted scripts for the data on the other. This loosens the cohesion between schema and data changes and eventually becomes a pain in the butt, especially in a project with multiple production databases.
With the state-driven approach, we end up with messy hook-up scripts for pre-execution:
-- Pre-execution script
IF @Version > 15 AND @Version <= 25
BEGIN
-- Create a temp table with the Cusomer names
CREATE dbo.tmp_CustomerNames(ID int , Name)
END
IF @Version > 25 AND @Version <= 28
BEGIN
...
ENDAnd post-execution steps:
-- Post-execution script
IF @Version > 15 AND @Version <= 25
BEGIN
-- Fill the new First Name and Last Name columns
UPDATE dbo.Customer
SET FirstName = fn_Split(c.Name, 0), LastName = fn_Split(c.Name, 1)
FROM dbo.Customer c
INNER JOIN dbo.tmp_CustomerNames n ON n.CustomerID = c.CustomerID
DROP TABLE dbo.tmp_CustomerNames
END
IF @Version > 25 AND @Version <= 28
BEGIN
...
ENDWith these hook-ups, it’s hard to overlook the whole picture of what is going on with the database as you need to assemble this picture from 3 different places.
The migration-driven approach, at the same time, handles this problem with ease. The migrations themselves may contain scripts for both schema and data upgrades. The cohesion between them comes out naturally, without any additional effort.
What approach to choose?
So the state-driven approach is good at handling merge problems while the migration-driven - at dealing with data migrations. What approach to choose? To answer this question, we should look at the problem from a slightly different perspective.
I strongly believe that a heavy use of stored procedures and database functions breaks the Separation of Concerns principle. Application logic should be stored in the application code, not in the database. This applies not only to C#/Java/etc code but also to SQL code. If you need to use any SQL within your application, go ahead but be sure you put this code in your application code files.
Ideally, a database should become a dump storage which doesn’t know how to deal with data in it. A project where the SoC principle is properly applied doesn’t contain many (if at all) stored procedures and functions, only tables, views, and the data in them.
In such projects, merge problems are not as big of a problem because of the lack of logic inside the database. Therefore, the migration-driven approach does the best job possible in such projects. I talked about best practices that regard to this approach in the previous post, so be sure to read them.
Does it mean we should always use migrations for maintaining our databases? Not at all. There still are some cases where the state-driven approach is applicable.
One of such cases is legacy projects. If you are working on a project which heavily relies on logic baked into the database, you might not be able to extract that logic out to the application code. If there is a large team of developers working on this project, the use of the state-driven approach might be the best choice as it allows for alleviating merge problems when it comes to stored procedures and database functions.
Another valid use case would be a small project that is not yet shipped to production. Usually, you don’t have to worry about data in such projects, so you can just wipe all of it out and re-create the whole database from scratch whenever you need to upgrade it. This approach allows you to quickly sketch your database without putting a lot of effort in building proper migration scripts. None the less, be sure to switch to the migration approach after the project is deployed.
Summary
This post was inspired by an NDC talk given by Alex Yates. Check it out if you want to learn more on this topic.
Let’s summarize:
-
The state-driven approach is good for projects with a lot of logic in the database and a large team working on it. You are also better off choosing it for small projects that are not in production yet.
-
The migration-driven approach is a better choice in all other cases.
Other articles in the series
-
State vs migration-driven database delivery
Subscribe
Comments
comments powered by Disqus







