SQL vs NoSQL: you do want to have a relational storage by default
The concept of NoSQL databases has been around for a while, but there still are quite a few misunderstandings regarding the topic of relational SQL vs NoSQL databases. In this post, I’d like to clarify the most common misconceptions and discuss the primary use cases for each of them.
Are NoSQL databases really schemaless?
A quick note before we start: the notion of NoSQL refers to 4 different types of databases: Document-Oriented, Column-Oriented, Key-Value stores, and Graph DBs. In this post, I talk about Document-Oriented databases primarily. I refer to them as NoSQL for the sake of brevity but keep in mind the term itself has a more broad scope.
Alright, so are NoSQL databases really schemaless? Let’s take an example. Let’s say we have a document collection named Customers with the following data inside:
{ Id: 1, Name: "John Doe" },
{ Id: 2, Name: "Bob Smith" }
Because of the collection’s schemaless nature, nothing prevents us from adding another document, like this:
{ Id: 1, Name: "John Doe" },
{ Id: 2, Name: "Bob Smith" },
{ Id: 3, FirstName: "Alice", LastName: "Christopher" }
Now, let’s say we have a method that looks for customers given a particular name:
public class CustomerRepository
{
public IReadOnlyList<Customer> Find(string name)
{
return _collection.Find(x => x.Name == name).ToList();
}
}
What would happen if we add Alice Christopher to the collection the way we did previously? Would the Find method find her? Surely, not. The repository class implicitly relies on the collection schema and require all customers to have the Name property in order to be detected. In this scenario, we have to adjust the Find method so that it would start looking at both Name and FirstName/LastName properties.
While NoSQL databases are technically schemaless meaning that they allow us to store documents in any shape we want, the notion of schema itself doesn’t vanish from our domain model. Schemaless databases just shift the responsibility to maintain the schema to us, developers.
The use of a NoSQL storage means a move from explicitly defined data structures to implicit ones. And that is a huge step back from what we have in relational databases, because, as we know, we should always try to make implicit assumptions in our code explicit.
And of course, the notion of schemaless data doesn’t belong to NoSQL databases exclusively. We can do the same in traditional relational databases. For example, one could serialize the whole customer object to an XML or JSON document and put it to an MSSQL/Oracle/MySQL table. This would make the customer storage schemaless as well.
As you might guess, such design decisions are frowned upon in the world of relational databases because of the lack of explicitness. Explicit schema SQL storages introduce is a great assistant when it comes to defining data structures. It helps developers make sure the shape of the data they work with is consistent across the whole database.
Are schema migrations easier with NoSQL databases?
Another broadly accepted statement is that schema migrations are easier with NoSQL databases. Are they?
In the example above, how would we handle the two editions of the customer data? We would need to introduce schema versioning:
{ Id: 1, Name: "John Doe", Version: 1 },
{ Id: 2, Name: "Bob Smith", Version: 1 },
{ Id: 3, FirstName: "Alice", LastName: "Christopher", Version: 2 }
It means that in any given time there exist at least 2 versions of the Customer class and we have to handle both of them in our domain model manually:
public class Customer
{
public int Id { get; private set; }
public string Name { get; private set; }
public string FirstName { get; private set; }
public string LastName { get; private set; }
public int Version { get; private set; }
/* Other members */
}
public class CustomerProcessor
{
public void Process(Customer customer)
{
string lastName;
if (customer.Version == 1)
{
lastName = /* Get the last name out of customer.Name somehow */;
}
elseif (customer.Version == 2)
{
lastName = customer.LastName;
}
else
{
throw new InvalidOperationException();
}
/* Work with lastName here */
}
}
The situation here is essentially the same. NoSQL databases don’t help us with the schema migrations, they transfer the obligation to perform it to us, developers. With a non-relational storage, we have to do the following:
-
Change our code so that it handles both versions of the schema (see the CustomerProcessor.Process method).
-
Create a background job which searches for documents of the old versions and transforms them into the new version, one by one.
Now, compare this to the explicit "fire-and-forget" migrations we can employ in an SQL database. All we have to do there is write a single script that would handle all data migrations at once. The migration logic in relational storages tends not to infiltrate to the domain model which helps keep the latter clean and simple.
Schema migrations in NoSQL databases are not easier. Contrarily, they are more difficult to implement and maintain comparing to SQL storages.
Other benefits of traditional SQL databases
There are two more benefits traditional SQL databases provide us out of the box. There’re no analogues for them in most Document-Oriented DBs.
The first one is data (referential) integrity. This feature helps us verify we don’t reference non-existing rows and thus keep the data consistent in the first place. For example, we can create a foreign key constraint in our customers table and thereby make sure all our customers belong to one of the predefined countries:
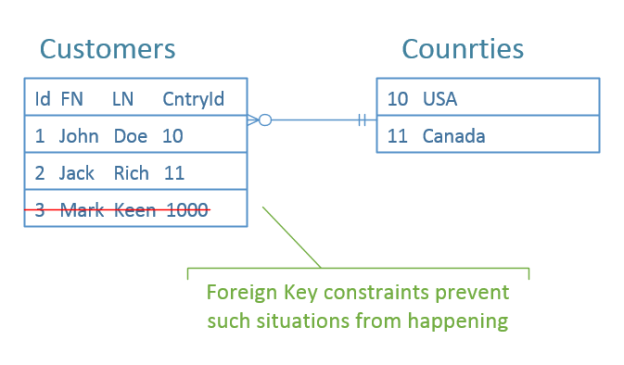
A relational database acts here as the last stand guardian, so to speak. It means that we still need to employ proper validation in the application code ourselves but if we miss something, that wouldn’t lead to data corruption. The database would inform us about the inconsistency by rejecting the incorrect transaction.
In NoSQL storages, we have to - once again - handle such situations manually. It’s a common practice to create a background job to reveal inconsistent data and try to settle the conflicts after they took place.
Atomic transactions across different tables and/or rows is the other benefit. It’s not as important as those we discussed previously because a well-designed NoSQL storage rarely requires the change of multiple documents at once. But still, it’s a nice-to-have feature in many cases. NoSQL databases usually support atomic operations within a single document only.
So why ever bother choosing a NoSQL data storage?
Despite all the merits relational databases have, they lack two important ones: scalability and performance. And this is the only reasons why one should ever consider choosing NoSQL. Not because NoSQL database are schemaless (they are not, essentially), nor because they make schema migrations easier (they don’t). Scalability. And performance.
Relational databases are Jacks of all trades. They provide rich functionality out of the box. They also do pretty well with any kind of software. The only problem with SQL storages is that when your data outgrows a single database instance, you no longer can rely on the relational model.
If that is the case, you have to revisit your application and try to accommodate a NoSQL storage - one that fits the needs of your software the most:
But even in this case, it doesn’t mean you should forgo the SQL database completely. You can employ a NoSQL storage for the part of your system that doesn’t fit the relational model and keep the rest in place. This practice is called Polyglot Persistence.
All said above doesn’t mean you can’t scale a relational DB. You can (to some extent). But this means you will need to give up on the benefits it provides, such as data integrity. Also, SQL databases don’t provide such functionality out of the box, so it often becomes a pain to do that. In most cases, you are better off just choosing a NoSQL DB for scalability purposes.
SQL vs NoSQL: Conclusion
In most cases, NoSQL is a forced choice. It’s a tool the use of which you want to postpone as much as possible as it shifts too much of burden to you as a programmer. Relational databases are more friendly, they provide rich capabilities out of the box:
-
Explicit schema
-
The ease of migrations
-
Data integrity
-
Atomic transactions across several tables/rows
If your application is not expecting outstanding scalability requirements in any near future, you are almost always better off choosing a relational storage. The reason is that non-relational databases require constant (and quite big) maintenance overhead comparing to relational ones.
Only if you are sure your system will contain more than tens or hundreds of millions rows in a single table, should you consider using NoSQL. And even in this case, try to extract to the non-relational storage only the parts that don’t fit the relational DB. That would help reduce the overall maintenance overhead.
Related articles
Subscribe
Comments
comments powered by Disqus







