REST API response codes: 400 vs 500
Today, I’d like to talk about the (sometimes subtle) difference between 4xx and 5xx response codes when programming a RESTful API. I’ll try to show when to return what code (400 or 500) and introduce a simple way to implement this logic on the server side.
400 and 500 response codes from a programmer perspective
In REST, both 4xx and 5xx types of codes denote an error. The main difference between the two is whose fault that error is. A 4xx code indicates an error caused by the user, whereas 5xx codes tell the client that they did everything correctly and it’s the server itself who caused the problem. 401 (unauthorized), 403 (forbidden), 404 (not found), and so on all mean the client has to fix the problem on their side before trying again. On the contrary, 501 (not implemented), 502 (bad gateway), etc mean the request can be resent as is at a later time, when the server overcomes its current problems.
This difference is very similar to the topic of exceptions and validation errors. The guidelines here coincide almost exactly. 5xx response codes in web services are basically unexpected situations in the exceptions terminology. Essentially, all 5xx errors mean either software failures (such as bugs and configuration issues) or hardware failures (such as server outage).
Following this analogy, 4xx response codes correspond to validation errors. If the external request is incorrect for some reason, you don’t let this request through and instead return the user an error message.
Here’s a picture from my Functional C# Pluralsight course which shows this difference:
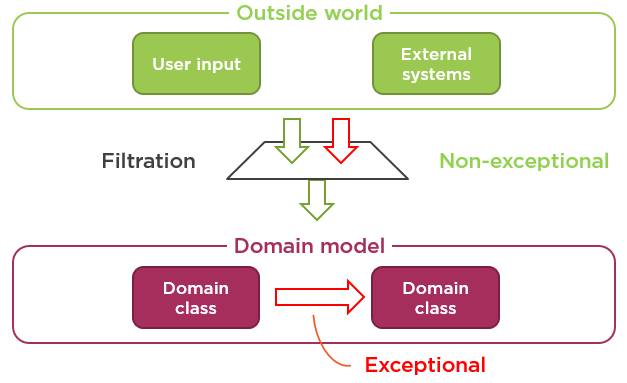
You can think of validation as of filtration. Only valid messages are allowed to come from the outside world, the rest of them are simply dropped with an explanation of what the user did wrong. There’s nothing exceptional in the act of filtering those incorrect messages out, it’s a routine operation, and thus it shouldn’t be implemented using exceptions. Otherwise, we’d face all the bad consequences of using exceptions to control the program flow. The validation is usually performed at the border of your bounded context, in application services (controllers and view models).
It’s a different situation when the message comes not from the outside world but from one of your domain classes. This could be due to one of three reasons. You either haven’t filtered an incorrect external request and let it through, or the domain class generates them on its own which means there’s a bug in it. It also could be that some external system, for example the database, returns a result you don’t know how to deal with.
All these three situations are unexpected. You can’t possibly expect your system to contain bugs. Otherwise, you would fix them in the first place. And you also expect assumptions you make about external systems to be held at all times. For instance, that your database is always online. Otherwise, they wouldn’t be assumptions.
Unexpected situations constitute a dead end for the currently executed operation. The best thing you can do if you run into one is interrupt the operation completely and stop the spread of inconsistency in your application. This is the essence of the Fail Fast principle.
How to handle 400 and 500 response codes
Alright, that’s enough of a groundwork. What about REST API response codes? There’s a direct mapping between the two concepts. All unexpected situations in your web service map to 5xx codes. All validation errors - to 4xx ones.
Sounds simple, but what does that mean to us programmers? There are several corollaries from that.
1. All unhandled exceptions should result in a 500 response code. The fact there’s an unexpected situation in your software has nothing to do with the user’s request, it’s clearly an issue on the server side, hence the 500 code. Unexpected situations show themselves up as unhandled exceptions: either bugs or hardware failures.
2. Put a single generic handler to the very top of your execution stack to handle all 500 errors. It’s difficult to deal with unexpected situations in any other way because, by definition, you can’t possibly know where they might happen. Also, return just a generic response message with the 500 code. No need to dive deep into the technical details here as the user won’t be able to make use of this information anyway.
3. Handle 400 errors separately and provide a thorough error message for each of them. Unlike 500 errors which the user can’t do anything about, 400 errors are all their fault. Therefore, you need to clearly state what that error was and how the user can avoid it in the future. The only way to accomplish it is to handle each validation error separately.
4. Never return 500 errors intentionally. The only type of errors you should be showing to the user intentionally is validation (400) errors. 500 codes are all about something you don’t anticipate to happen.
Note that while the difference between 4xx and 5xx groups of codes is important, the distinction between codes inside these groups is not. While it’s preferable to show the exact reason of why a particular request has failed (wrong URL, authentication is required, etc.), by the time a request makes its way through the framework’s layers to your code, most of those standard 404 and 401 causes are already filtered, and so you, as a programmer, can just return 400 for all remaining validation errors and 500 for server ones.
Alright, the first 3 points above are pretty self-explanatory but I think the 4th one needs elaboration. Why is that you should never return a 500 error to the user intentionally?
The explanation here is tricky. Recall that all 500 errors correspond to unexpected situations in your system: bugs and hardware failures. The moment you start doing something to handle that particular unexpected situation, it becomes an expected one. At this point, two things can happen. If it’s a bug, you simply fix it and the unexpected situation disappears completely. If it’s an incorrect user input which wrongly passed the validation, you modify the validation rules so that no such input can go through them anymore.
You can think of this process as of closing a loophole where you convert an unexpected situation into an expected one and thus eliminate that potential reason of failure.
Here’s an example:
public class CustomerController
{
[HttpPost]
public IHttpActionResult RegisterCustomer(string name)
{
var customer = new Customer(name);
_repository.Save(customer);
return Ok();
}
}
public class Customer
{
public string Name { get; private set; }
public Customer(string name)
{
if (string.IsNullOrWhiteSpace(name))
throw new ArgumentException(nameof(name));
Name = name;
}
}
This controller method registers a new customer. If we try to pass an empty name, it will throw an exception which will result in a 500 error. This error constitutes a bug: we haven’t validated the user input properly. The customer name in this example can’t be empty.
In order to fix it, we need to add validation:
public class CustomerController
{
[HttpPost]
public IHttpActionResult RegisterCustomer(string name)
{
if (string.IsNullOrWhiteSpace(name))
return BadRequest("Customer name can't be empty");
var customer = new Customer(name);
_repository.Save(customer);
return Ok();
}
}
Now the attempt to pass an empty customer name will result in a 400 response code with a detailed message regarding what the user did wrong. The loophole is closed.
If you need a detailed example of how to implement a generic handler for 500 errors or handle validation errors without the use of exceptions, check out the last module of the Pluralsight course I referred to earlier. Or you can go straight to its source code which I’ve put on Github.
Never mask server failures behind 400 responses
Every 500 error indicates a problem on your side. The more 500 responses your system returns, the more unstable it appears for end users. Ideally, you want to eliminate this class of errors completely. However, it' important to note that although 5xx errors are unwanted, you shouldn’t pretend they never happen. If there’s a problem on the server side, state it clearly. It will help avoid frustration among your users and also let you track them down more easily.
On a project I participated in some years ago, there was a bug in the data access layer. The details of the bug are not important here. What important is the way the system handled that bug. Instead of returning a 500 response code (which you would normally expect from a RESTful application), that system replied with a 400 response. The code looked something like this:
[HttpPost]
public IHttpActionResult RegisterCustomer(string name, string address)
{
try
{
var customer = new Customer(name, address);
_repository.Save(customer);
return Ok();
}
catch (Exception ex)
{
// All exceptions get converted into 400 errors
return BadRequest("Invalid request: " + ex.Message);
}
}
As you can see, all exceptions here get converted into 400 response codes. This is clearly a violation of the Fail Fast principle and should be avoided. In this particular case, it leads to confusion: users think it’s them who did something wrong when trying to register a customer whereas it was a bug on the server itself. Needless to say, such approach didn’t help the team to find and fix the problem as it was hidden behind a seemingly innocent validation response.
Summary
Alright, let’s summarize:
-
4xx codes indicate errors caused by the user. They are basically validation errors.
-
5xx codes indicate errors caused by the server itself. They are unexpected situations (bugs and hardware failures).
-
It’s important to differentiate the two. It’ll help inform users about how they can fix the problem if it appears to be on their end, and it will also help you track and fix problems on the server side. Never mask server failures behind 400 responses.
-
There are some simple guidelines regarding how to handle 400 and 500 errors.
-
All unhandled exceptions should result in a 500 response code.
-
Put a single generic handler to the very top of your execution stack to handle all 500 errors.
-
Handle all 400 errors separately and provide each of them with a thorough error message.
-
Never return 500 errors intentionally. The only way your service should respond with a 500 code is by processing an unhandled exception.
-
Subscribe
Comments
comments powered by Disqus







