Pragmatic integration testing
The topic described in this article is part of my Unit Testing Pluralsight course.
When trying to break down unit testing, the bigger picture stays incomplete if you overlook the subject of integration testing. In this post, we’ll discuss how to make the most out of your integration tests with pragmatic integration testing.
Integration tests are tests that, unlike unit tests, work with some of the volatile dependencies directly (usually with the database and the file system). They can potentially interfere with each other through those dependencies and thus cannot run in parallel.
Pragmatic integration testing
By focusing your effort on unit testing against public API of the SUT, you are able to get the most out of your investments. Unit tests that verify either the SUT’s output or its state are the most valuable as they provide the best signal/noise ratio: they have a good chance of catching a regression error and they also have a low chance of generating a false positive.
However, they aim at testing highly isolated domain classes only. The ones that we separated from volatile dependencies:
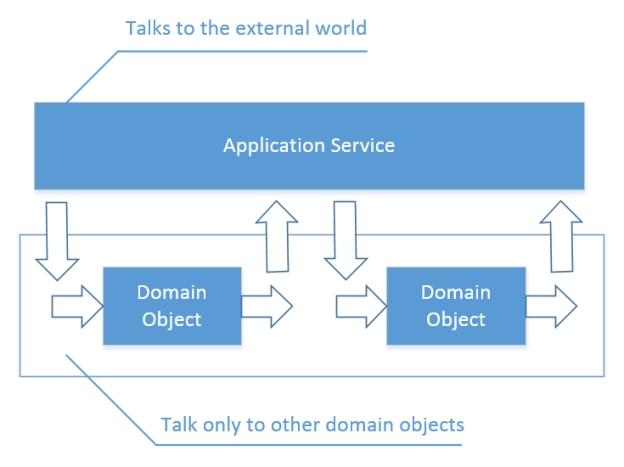
The coordination logic which resides in application services is left uncovered by such tests. While that’s certainly an issue, a proper solution for it would be using integration tests, not unit tests with mocks.
When you implement the separation of concerns I described in the previous article, the application services become thin, they don’t contain any domain knowledge. Because of that, unit testing them by replacing all volatile dependencies with test doubles doesn’t provide much of additional value. The amount of real code that gets exercised in such tests in addition to the existing unit tests is minimal as the logic in the application services themselves is quite trivial. It means that such tests don’t have a significant chance of catching a regression.
What you can do instead is you can cover application services with integration tests that will touch some of the volatile dependencies (at least the database and the file system). Such integration tests have a much better value proposition because they do traverse a significant amount of real code and thus have a good chance of catching a regression. They also have a low chance of raising a false alarm because they verify the state the volatile dependencies ended up getting into, not the way the SUT communicated with them. The downside here is that integration tests achieve these benefits at the expense of being slow.
Working with volatile dependencies you don’t control
Not all volatile dependencies can be covered by integration tests, though. While dependencies can be categorized as stable and volatile, volatile dependencies themselves also fall into two categories: the ones you can control and the ones you don’t have control over. The former is usually the resources which your application owns entirely: the database and the file system. Examples of the latter are: SMTP service, message bus, 3rd party API.
So, what to do with dependencies your application doesn’t control? That is where mocks can actually be helpful and that’s what I personally consider the only justified use case for them (not entirely justified, though; more on this below).
Let’s look at the 3rd style of unit testing - collaboration verification - once again:
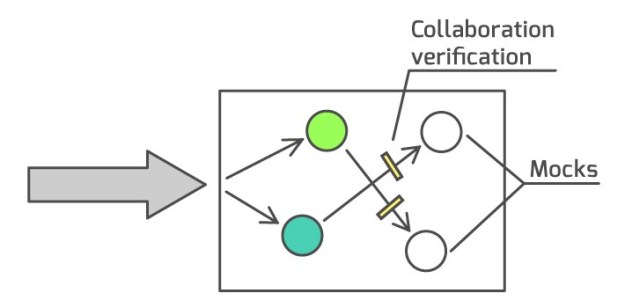
The problem with this approach is that the collaboration pattern between peers inside your domain model is not part of their public API, it’s an implementation detail. You can change it however you like and as long as the system produces the same output and leaves the same side effects, you shouldn’t care how exactly it does it.
However, communications with external systems - the volatile dependencies your application doesn’t own - is a different matter. Unlike collaborations between domain classes inside your domain model, the way your domain talks to the outside world does comprise its public API. Such collaborations is the contract your system must hold at all times.
That distinction grows from the way separate applications relying on each other evolve together. You cannot just change the communication protocol in one of them, that would break all other systems that integrate with it. For example, if you modify the format of the messages your application emits on the bus, the integrated systems won’t be able to understand them anymore. When it comes to communicating with the outside world, you have to preserve backward compatibility regardless of the refactorings you perform.
Volatile dependencies your application doesn’t control is the only place where collaboration verification can and should be employed:
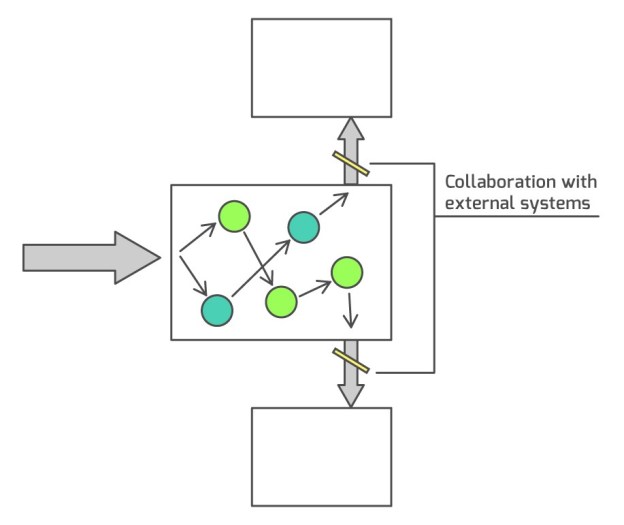
This is an important point, so let me re-iterate on it. The way your domain objects communicate with each other is an implementation detail whereas the way your application collaborates with other applications is part of its public API. The latter is the contract, the post-conditions your system must guarantee to fulfill. And it’s your responsibility to make sure they are held.
Note that when working with volatile dependencies which you don’t have control over, you need to always wrap them with your own gateways. Also, it is legitimate to introduce interfaces for such dependencies even if the sole purpose of doing so is to enable integration testing. Here’s an example of such an integration test: link.
Mocks vs stubs/spies from the value proposition point of view
Now I’d like to expand on the remark that while collaboration verification is perfectly reasonable to ensure integrity with external systems, you don’t necessarily have to use mocks for that. But before that, let me give you a refresher on the differences between mocks, stubs, and spies.
A mock is a test double which allows you to verify that some method was invoked during the test. It also lets you make sure this method is called using some particular parameters. A stub, on the other hand, is a test double that just returns some canned answer when you ask it. A spy is a test double that allows you to record calls to some methods and examine them later on manually (although, some authors also use the term "stub" for this kind of activity).
The term "mock" is also used to denote an instrument, a special tool that enables you to create test doubles:
var mock = new Mock<IEmailGateway>();
Mock as a test double does not equate to Mock as a tool. You can use a mock-the-tool to introduce either a mock-the-test-double or a stub. Here’s an example:
[Fact]
public void Test_with_a_mock()
{
var mock = new Mock<IEmailGateway>();
var sut = new Controller();
sut.GreetUsers(mock.Object);
mock.Verify(x => x.SendGreetingsEmail("[email protected]"));
}
[Fact]
public void Test_with_a_stub()
{
var stub = new Mock<IDatabase>();
stub.Setup(x => x.GetNumberOfUsers()).Returns(10);
var sut = new Controller();
Report report = sut.CreateReport(stub.Object);
Assert.Equal(report.NumberOfUsers, 10);
}
The first test creates a mock-the-tool and uses it to make sure the SUT invoked the correct method on the IEmailGateway interface. The second test also creates a mock-the-tool but instead of checking what members of it were invoked, it uses the tool to set up a canned answer for the GetNumberOfUsers method.
This is essentially what differs a mock from a stub: mocks are used for verifying side effects whereas stubs - for providing the SUT with test data. Another way of thinking about these differences is using the terminology from the CQS principle: mocks are for commands; stubs are for queries.
It’s perfectly fine to use a mock-the-tool as long as you do that in order to produce stubs for your application services under test. This tool can indeed be very beneficial for that matter.
However, try to refrain from using mocks-the-test-doubles even when you need to substitute a volatile dependency you application doesn’t control. Use spies instead. The test with a mock above can be rewritten using a spy, like this:
[Fact]
public void Test_with_a_spy()
{
var gateway = new FakeEmailGateway();
var sut = new Controller();
sut.GreetUsers(gateway);
gateway.SentNumberOfEmails(1)
.WithEmailTo("[email protected]");
}
And here’s the spy itself:
public class FakeEmailGateway : IEmailGateway
{
private readonly List<string> _sentEmails;
public IReadOnlyList<string> SentEmails => _sentEmails;
public FakeEmailGateway()
{
_sentEmails = new List<string>();
}
public void SendGreetingsEmail(string to)
{
_sentEmails.Add(to);
}
public FakeEmailGatewaySentNumberOfEmails(int number)
{
Assert.Equal(_sentEmails.Count, number);
return this;
}
public FakeEmailGatewayWithEmailTo(string email)
{
Assert.Contains(_sentEmails, x => x == email);
return this;
}
}
So, what are the benefits of using a spy over a mock? There are two of them.
Firstly, you can set up the spy to gather only the information you need to verify, nothing more. It’s often the case that you need to provide quite a few of parameters to an external dependency in order to make it work but at the same time, you might not want to check all of them.
With an email gateway scenario, you may be ought to provide 3 pieces of it: the recipient email address, the subject, and the email body. At the same time, you may decide to verify only the first two components, not the email body itself. A spy allows you to explicitly specify what information you are interested in testing. In the code sample above, we are gathering only recipient emails.
Secondly, the spies can be made reusable. And that allows you to gain additional protection against false positives. If the interface of the external dependency changes, you will need to modify only the spy itself, not the tests using that spy.
Conclusion
Overall, all these techniques allow you to gain the most out of your test suite (which consists of both unit and integration tests). When you isolate your domain model from volatile dependencies, you are able to test domain classes against their public API (either their output or state) which, in turn, result in a good chance of catching a bug and a low chance of getting a false positive. Make sure all notable domain knowledge in your domain classes is covered by unit tests.
Integration tests, on the other hand, provide guarantees that your application works with the external dependencies correctly. The dependencies the application owns are exercised directly; for all other external dependencies, integration tests verify the way your system collaborates with them and make sure it stays unchanged.
As integration tests is a much slower option comparing to unit tests, use them to cover the most important code paths only: happy paths and sophisticated edge cases.
Most likely, you will not achieve 100% test coverage if you adhere to the practices described here but that shouldn’t be your goal anyway. Just like any other extreme, 100% test coverage requires too much work most of which simply doesn’t pay off. With the techniques I described in the previous posts, you are able to cut off most of it without degrading the value of your test suite. In other words, you are able to achieve firm confidence with less amount of test code and therefore maximize the return on the effort you put into it.
Summary
-
The communication pattern inside your domain model is an implementation detail; the way your application communicates with the outside world is part of its public API.
-
Include volatile dependencies your application owns into your integration test suite; use test doubles to verify communications with the volatile dependencies you don’t have control over.
-
There’s a difference between the concept of mock-the-tool and mock-the-test-double.
-
Prefer using spies over mocks-the-test-doubles.
In the next post, I’ll provide a review on the GOOS book along with an example of refactoring away from collaboration verification to verifying the observable state of the SUT. I’ll also show how to implement in practice the architectural changes we talked about in the Pragmatic unit testing article.
Other articles in the series
Related articles
Subscribe
Comments
comments powered by Disqus







