OOP, FP, and object-relational impedance mismatch
Today’s topic is gonna be about OOP, FP, and object-relational impedance mismatch. The goal of this article is to show how object-oriented and functional paradigms deal with relational data stores.
Object-relational impedance mismatch
The object-relational impedance mismatch is basically the set of difficulties that arises when you try to combine an object-oriented code with a relational database. Before we get to the topic of this post, let me re-iterate on what those difficulties are. The following 3 items is a list of them. It’s not an exhaustive one, but I think they are responsible for most problems we experience in practice.
1. Relations vs object references
The first difference between OOP and relational databases is in how they represent connections between separate concepts. In OOP, those connections are direct references from one concept to another. They can be of various cardinality: a class may either reference a single instance of another class or a whole collection of them. They also can be of various parity: uni- or bi-directional. If latter, classes connect to each other simultaneously, thereby forming two references, one at each side of the connection.
In relational databases, connections between concepts are represented by relations. There’s no inherent notion of cardinality in databases. A link between two tables is just that - a link. There’s nothing in that link telling us whether it is a one-to-many, many-to-many, or some other relationship. It is us who put a meaning into it and interpret that link one way or another depending on the context.
Here’s for example, a connection between two tables:
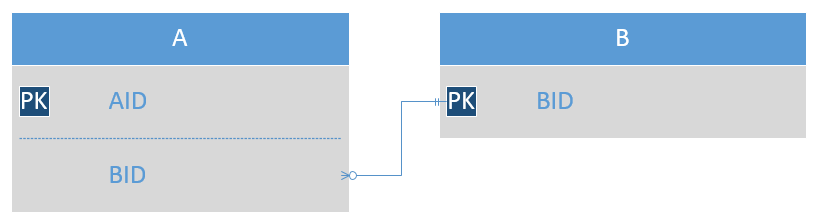
Can you say which type of relationship that is without knowing the tables' semantics? No, you can’t. If you have some experience with entity-relational modeling, you can probably narrow down the possible interpretations to two options: one-to-many or many-to-one.
For example, if A is Product and B is ProductType, then it’s most likely a many-to-one relationship. In other words, many products can refer to a single product type. Similarly, if B is Log and A is LogEntry, then it can be a one-to-many relation. A single log instance can contain multiple entries.
It can also be a one-to-one relationship. For example, a person might reference an address record which is not shared across other people. And of course, it can be both one-to-many and many-to-one in case of a bi-directional connection.
Sure, there are some configurations in which the type of the relationship is definite. Also, many developers are really used to do this type of analysis, so they don’t even notice the lack of important information here. But generally, the concept of cardinality is not something that is built into relationships themselves. The way we interpret them highly depends on the context, we can’t draw any conclusions outside of that context.
By the way, it’s the same situation as with normalization. We can’t say which normal form a database resides in without analyzing data semantics.
When trying to marry a relational database with an object-oriented code, uni-directional references usually pose the least amount of friction. You just declare a link in one of the two connected classes, and that’s it. For example, for this type of database:
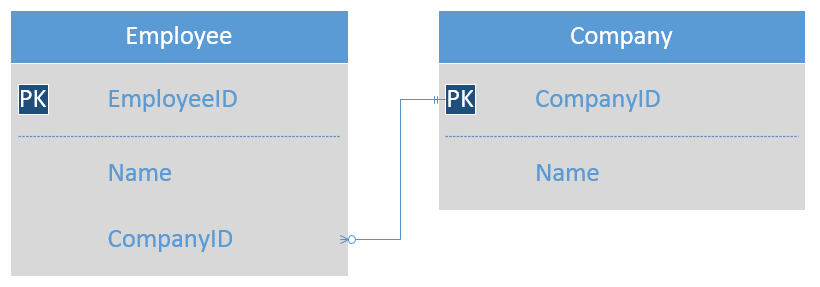
You might have the following application code:
public class Employee
{
public string Name { get; private set; }
public Company Company { get; private set; }
}
public class Company
{
public string Name { get; private set; }
}
And it’s really easy to maintain this kind of relationship.
Problems arise when you try to form a bi-directional relationship between classes. The most significant of which is maintaining integrity. It’s now not enough to just update a reference on a single instance, you need to keep track of both sides of the connection in order to ensure consistency.
In the example above, the Company class might have a collection of employees:
public class Employee
{
public string Name { get; private set; }
public Company Company { get; private set; }
}
public class Company
{
public string Name { get; private set; }
public List<Employee> Employees { get; private set; }
}
And it’s now your responsibility as a developer to maintain both ends: the reference on one side and the collection of references on the other. So whenever you update an employee’s company, that employee must be removed from the old company’s collection of employees and added to the new one. Similarly, when you move an employee from one company to another, you must not forget to update his Company property.
Note that there’s no such problem in the relational world. There’s no such notion as uni- or bi-directional relationship. Any type of connection is represented using a single link. If you need to transition an employee to another company, you need to just update that link, and that’s it.
This is one of the reasons why it is important to keep an eye on such things. Whenever possible, try to reduce cardinality by decreasing the number of "manies" in relations (many-to-many → one-to-many/many-to-one → one-to-one). Also, try to replace bi-directional relations with uni-directional ones when you can.
2. Flat vs hierarchical structure
This point mostly flows from the previous one. In the OO world, the fact that you operate direct references often leads to hierarchical data structures. You usually end up with clusters of classes: a root, the main class so to speak, and some number of descendants. Moreover, this hierarchy may be a cycled graph. A structure where some group of classes reference each other forming a cycle.
In relational databases, the situation is different. As there’s no such things as uni- or bi-directional relationships and no inherent notion of cardinality, a relational model tends to result in a flat structure where each table is of the same rank as any other one. Cycles can occur in databases too but they are not as common and generally are frown upon.
The most significant issue that comes as a result of this disparity is maintaining transactional boundaries. In OOP, you can choose to declare a particular cluster of classes a single thing, an aggregate, and then decide to operate that thing transactionally.
The problem here is that in the relational data store, there’s nothing we can do to enforce this kind of separation. All tables are made equal, so any transaction can update any number of tables at once. Because of that, it’s easy to introduce a race condition. A situation where one transaction updates two tables and another transaction updates one of those tables as part of another routine, leaving an inconsistency between the two. It’s impossible to completely prevent such issues from happening.
3. Encapsulation
And that leads us to the next difference: the way the two paradigms treat encapsulation. In the relational modeling, there’s just no such notion. Encapsulation is not something you worry about when trying to come up with a database scheme.
On the other hand, encapsulation is huge when it comes to objects. You usually want to hide as much information as possible by default and reveal it only when necessary. And even then probably change the form of that information to something customer-friendly and not expose its underlying structure.
For example, for this database table:

You might want to expose only the details relevant to the clients of your class:
public class Customer
{
public string Name { get; private set; }
private decimal _totalPurchaseAmount;
public bool IsPreferred => _totalPurchaseAmount > 10000m;
}
In other words, transform the decimal TotalPurchaseAmount into a boolean IsPreferred.
And the tendency to encapsulate everything doesn’t stop here. It’s often preferable to hide not only parts of tables but also tables themselves. In OOP, we treat tables that help us form a many-to-many relationship as pure utility ones. We often don’t even show them in class diagrams. ORMs help us with that by leaving those tables behind the scenes when mapping a domain model to a relational database.
In the relational modeling, however, there’s no such thing as a utility table. As I mentioned earlier, all entities are made equal, no matter how small of large they are.
OOP, FP, and object-relational impedance mismatch
The three points outlined are not the only ones when it comes to object-relational impedance mismatch. For example, OOD introduces inheritance which is not supported by relational DBs. There also are some other distinctions. The three differences outlined above, however, are the most problematic; all others can be considered minor comparing to them.
Alright, so how all this relates to OOP and functional programming? It turns out that when it comes to combining application code with a database, these two choices - an object-oriented programming language and a relational data store - are the worst in terms of their suitability.
There’s no surprise, of course, and you should have noticed all the difficulties yourself if you ever used an ORM. The whole topic of object-relational mapping was even called the Vietnam of Computer Science and generated a lot of heated discussion over the years. (Here’s my portion of it by the way: Do you need an ORM?).
It doesn’t have to be that way, though, and there are some combinations that fit together much better. If we take OOP, FP, document and relational databases, here’s how we could depict them all in a single figure:
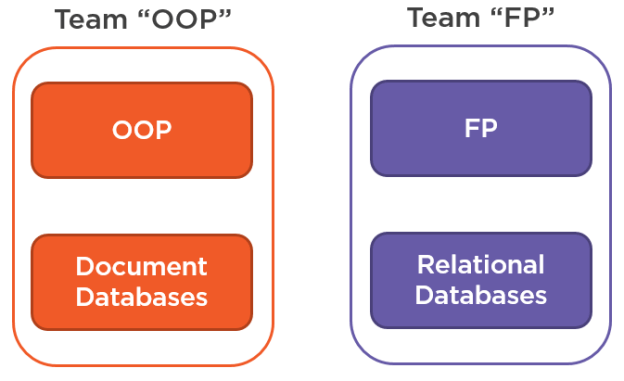
OO languages have much fewer paradigm differences with document databases than with relational ones. Similarly, functional programming gets along with relational databases much better than OOP.
I’m not saying there are no problems in the "Team OOP" or "Team FP" in terms of their fitness. There still are difficulties in these combinations. I’m also not saying that FP can’t possibly work with document databases, you definitely can build your functional code base on top of a document DB. However, the said technologies, if mixed in the above way, tend to result in much less problem comparing to the combination of OOP and RDBMS.
Let’s see how it is so.
Team "OOP"
When working with a document database from an OO language, you get quite a few perks right away, without even trying much.
First of all, you can make data in a document database hierarchical and thus mimic the class structure in your domain model. A document in this situation becomes a database version of the Aggregate DDD pattern: it contains all information about the aggregate root, the aggregate’s internal entities, and any value objects they may possess:
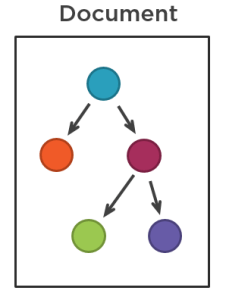
You also get almost ideal transactional boundaries for free. A single document is updated atomically which makes maintaining consistency inside an aggregate a trivial task. No race conditions between transactions (and no deadlocks, for that matter).
There’s no problem with connection parity and cardinality. A reference from one entity to another in a document DB is exactly that - a reference. Not a relation that you need to interpret as a reference.
In terms of parity, this could be a one-way reference:
// Person document
{
"Id": 11,
"Name": "Some person",
"CompanyId": 22
}Or two-way:
// Person document
{
"Id": 11,
"Name": "Some person",
"CompanyId": 22
}
// Company document
{
"Id": 22,
"Name": "Some company",
"MainContactPersonId": 11
}It’s just a matter of putting a new field to the document, pretty much the same way you would put a new property to your class.
In terms of cardinality, you also can explicitly state the type of the relation in the document itself. For example, here’s how you introduce a one-to-many relationship (the Contacts field):
// Company document
{
"Id": 22,
"Name": "Some company",
"Contacts": [ 11, 12, 13 ]
}
No need to dive into the data semantics, the presence of the array JSON type unambiguously shows us the relationship’s cardinality.
Also, the problem of mapping between the database and the application code is reduced tremendously as you don’t have to disassemble your objects into several tables and then assemble them back again when reading the DB.
And of course, proper encapsulation is much easier to implement when your data is nested and can be accessed only via the document root.
Team "FP"
Let’s now look at the other side of the aisle. The other two technologies that make a great match are functional programming and relational databases.
Again, that’s not to say that functional programming is impossible with document DBs, I see them fit together quite well too. But if you do need to use a relational DB, functional languages would most likely be a better fit.
So, how do they combine together?
First of all, their views on encapsulation are in agreement with each other. Both paradigms encourage you to use expose data. In functional programming, encapsulation doesn’t really matter that much because immutability makes it impossible to corrupt the internal state of your data structures. And if you want to introduce a friendly customer-facing API, you can create functions on top of those structures that transform them into something else.
When dealing with relational databases, we can split any type of work into two categories: read and write operations. The read part is where relational data stores and functional programming do exactly the same thing. It is the area where functional programming shines as this kind of operations fit it perfectly.
Think about it. When you write a SELECT SQL query, what you actually do is you create a pure function that gets some existing data from tables as an input and transforms them into something new. No side effects, no mutations.
For example, here:
SELECT FirstName + ' ' + LastName AS Name
FROM dbo.Person
WHERE PersonID = 1We have two functions combined together. The first one filters incoming rows by PersonID, and the second one takes the result of that filtration and transforms it into a new set of rows:
let select rows =
rows
|> Seq.filter (fun x -> x.PersonID = 1)
|> Seq.map (fun x -> x.FirstName + " " + x.LastName)And when you write user-defined functions in SQL, they should be immutable (purely functional) too.
So, as you can see, the functional paradigm is a perfect environment for querying and analyzing data.
As for manipulating it - not so much, but there are benefits here as well. Namely, you don’t need to worry about complex behavior attached to your data, it usually lives separately. And that - along with the lack of encapsulation - means you have fewer issues when translating data between the relational data storage and the functional data structures.
The main problem here is with writing to the database. More specifically, updating the existing rows. When doing so, you need to carry over the original ids of the entities you pull from the DB. Without it, you won’t be able to properly update those entities. And that spoils the otherwise clean picture as you now have to make sure that all transformations made to your records contain ids of the rows they came from.
There’s one design pattern which fits functional programming perfectly, though, even when you need to update the database. That is append-only architectures, like event sourcing. You don’t need to keep track of any state there because you don’t mutate anything. With event sourcing, you perform two operations both of which are purely functional: creating new immutable records and building projections on top of them.
So basically FP shines in those parts that don’t involve data mutation.
Another area where FP and relational database converge is in how they treat bi-directional relationships. As cyclic dependencies are generally disapproved of in the functional world (at least in F#), the way FP treats them looks very similar to what we have in relational modeling.
This is an example I brought earlier with a bi-directional relationship between Employee and Company:
public class Employee
{
public string Name { get; private set; }
public Company Company { get; private set; }
}
public class Company
{
public string Name { get; private set; }
public List<Employee> Employees { get; private set; }
}
As you can see, in C#, we would just have two classes referencing each other. In F#, however, the data model we’d come up with in order to avoid cycles will be very similar to what we have in the database:
type Employee = {
Name : string
}
type Company = {
Name : string
}
type CompanyEmployee = {
Employee : Employee
Company : Company
}The CompanyEmployee record here is basically the intermediate many-to-many table we would introduce in the database. If you need to show that there are two employees working in some company, you create two records of type CompanyEmployee. The same way you would create two rows in the intermediate database table.
Not only does this approach allow for eliminating cycles between records, but it also helps with maintaining consistency. Just as in the case of relational databases, there’s no need to maintain two sides of the relationship here. In C#, we the relationship consists of two parts: the Company property in the Employee class and the list of Employee`s in `Company. Here, the relationship is a single record. All you need to do is update that record; the connection between Employee and Company will never go off the rails.
Summary
The combination of OOP and a relational database is well-known but there are other combinations which make a better fit.
-
The problems that comprise the object-relational impedance mismatch are:
-
Differences between relations and object references. Relations don’t have an inherent notion of cardinality (many-to-one, one-to-one, etc.) and parity (uni-directional, bi-directional). We interpret relations one way or another depending on the context.
-
Flat vs hierarchical structure. All tables in a relational DB are made equal. In OOP, we tend to form hierarchical clusters of objects.
-
Encapsulation. In OOP, it is preferable to hide as much information as possible by default.
-
-
The two combinations that work better than the combination of OOP and RDBMS are "Team OOP" (OOP and document DBs) and "Team FP" (FP and relational DBs).
-
In the "Team OOP", document databases conform to OOP. They introduce hierarchical data structures, transactional boundaries, and relationships of various parity and cardinality.
-
In the "Team FP", functional programming does exactly the same thing as RDBMSs when reading from databases. And overall fits perfectly when you don’t need to mutate the existing data. It also encourages introducing data structure that mimic that of relational databases: with separate records for connections between entities.
Related articles
Subscribe
Comments
comments powered by Disqus







