KISS vs database normalization
In this article, I’d like to share an example of how the KISS principle can go against the database normalization principles and how to make a choice in such situation.
The example
Some time ago, I had a task which required me to implement linkage between the users of an application and their social accounts. At the time, we planned to add only two social providers - Facebook and Google - but others could be potentially integrated as well in the future.
What’s interesting in this feature is the discussion I had with my colleges regarding its implementation. The first version looked like this:
public class User
{
public string Name { get; private set; }
public IReadOnlyList<SocialAccount> Accounts { get; private set; }
}
public class SocialAccount
{
public SocialAccountType Type { get; private set; }
public string AccountId { get; private set; } // Assigned to the user by external provider
}
public enum SocialAccountType
{
Facebook,
Google
}
Every user was about to have a list of social accounts. Each social account would contain a type property stating what provider it is from and an identifier which is assigned by that provider to each unique user in the social network.
The database was going to have two tables: one for the users and another one for their social accounts. The relation between the User and SocialAccount tables is 1-to-many:
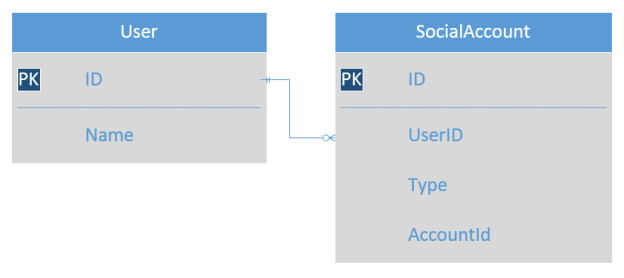
Seems reasonable, doesn’t it? Indeed, this design meets the requirements. Even more, it leaves a reserve for possible future enhancements: we will be able to easily add new providers just by extending the SocialAccountType enum and without updating our DB structure.
There’s nothing wrong with this implementation except one thing: we can make it simpler. Here’s what we can replace it with:
public class User
{
public string Name { get; private set; }
public string FacebookAccountId { get; private set; } // Assigned to the user by external provider
public string GoogleAccountId { get; private set; } // Assigned to the user by external provider
}

In this version, we’ve got rid of the account collection and introduced two separate fields instead. Also, we’ve inlined the SocialAccount table into the User table so that it now contains two columns with the currently integrated providers.
KISS vs database normalization
So, which version is better and why? Let me first bring the objections regarding the latter implementation.
First off, it’s not easily extensible. You will need to change the User class whenever a new social provider is added and that might end up being pretty burdensome. Secondly, the database here isn’t normalized: the table will contain lots of nulls in the two columns because, clearly, not all users would link their social profiles to the accounts in our system. This, in turn, would result in a waste of the disk space.
On the other hand, this design is simpler and fits the exact set of requirements we have right now.
You might have guessed where I’m going with this. The first version violates both of the two most important software development principles: YAGNI and KISS. It tries to predict the future needs by creating an extensible set of social providers and complicates the implementation of the existing requirements because of that.
Alright, but what about the drawbacks of the second version? Don’t they overweight the violation of these two principles? No, they don’t. In fact, they aren’t actually drawbacks.
New requirements tend to come in an unexpected form. Most likely, there would be details which we haven’t foreseen. That, in turn, would result in us making more effort to adapt the design comparing to the straightforward, right-to-the-point implementation. Keeping the code minimalistic prevents unnecessary complexity from creeping in and reduces the maintenance cost for the code base later on.
You might argue that with this design, we will have to modify the table schema in case we need to add a third provider. Sure, we will. But what’s the actual probability of this happening? Too often I saw extension points someone put into code stayed unused. Forever. And even if we are sure it’s not gonna happen, we are still better off with the simpler design. Remember, code is not an asset, it’s a liability. The latter version allows us to avoid bringing additional liability in up to the point where we really can’t get away without it, so it is still a much better deal.
The second objection - lots of nulls in the two Ids columns - isn’t an issue either. The days when the disk space was expensive have passed, fortunately. Besides, we are getting some performance improvements here due to the lack of SQL joins.
But I’m going to state the third objection against the single-entity design which I didn’t hear from my colleges. It just feels weird to inline columns from one table to another. Shouldn’t we always try to achieve the 3rd normal form as we’ve been taught in college? I definitely can relate to this feeling. Nevertheless, the answer is no: the KISS principle beats database normalization.
You should resist the temptation to normalize the DB structure in case it hinders design simplicity. A normalized database doesn’t automatically mean a good design. In fact, in some cases (like the one above), it makes it worse due to unnecessary complication.
Conclusion
Database normalization, like any other practice, shouldn’t be employed bluntly. Always try to make sure it serves the bigger goal of keeping the overall solution simple. If it doesn’t, don’t hesitate to deviate from this practice and denormalize tables in your DB.
Related articles:
- ← Entity vs Value Object: the ultimate list of differences
- Domain-Driven Design in Practice Pluralsight course →
Subscribe
Comments
comments powered by Disqus







