How to request information from multiple microservices?
This post is about how to work with information that is spread across multiple microservices.
How to request information from multiple microservices?
When you split your system into microservices, there’s a common problem that comes into play. That is how to best get information from all of those microservices.
Let’s say for example that you have an e-commerce application, and you decided to split it into three microservices. The first one is responsible for maintaining a product catalog with up-to-date descriptions. The second one figures out relationships between those products based on customers behavior ("You might also be interested in…" feature). And the third one is a price engine that sets up prices for each item.
When a client visits your web-site, you need to compose a nice looking page that involves all these three pieces of information: a list of products with descriptions, relationships between them, and prices.
How are you supposed to implement it?
Well, one way to do it is as follows:
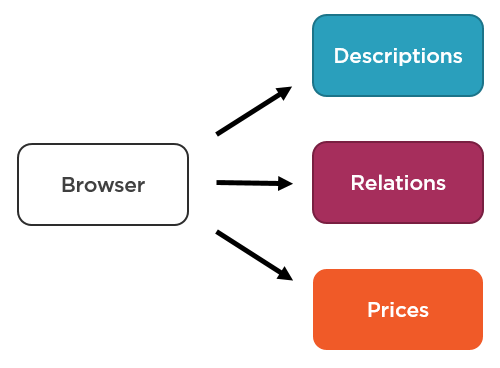
That is, make your browser fetch all the required information and then compose an HTML page out of it.
While this might be a viable solution in some cases, you usually want to have some kind of a front-end microservice that would be doing such work so that the client browser has only a single endpoint to connect with:
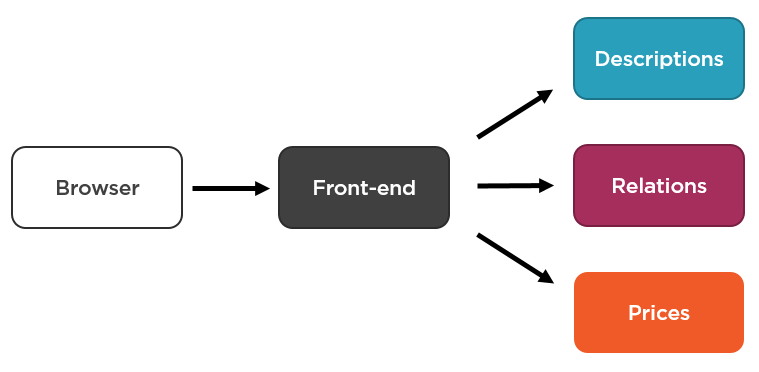
The above solution looks logical and it is also intuitive. This is exactly how we would implement it in the good old days with a single application-wide relational database at hand. We would just join information from the three "tables" and present the aggregated results to the caller.
Naturally, the first impulse is to do the same in the microservices environment: make the front-end call the other 3 services in the real time, pretty much mimicking the ad hoc behavior of SQL queries.
It turns out, though, that it is an awful solution. It kills your latency right off the bat. It might not be that noticeable with only 3 microservices (although in most cases, it is), but as you add up more and more of them, you will inevitably find yourself cornered. The front-end will have a hard time serving any requests whatsoever, they would just take too long as you would need to poll data from so many sources.
The reason here is that communication between microservices is an entirely different beast comparing to SQL queries. Whereas a typical SQL request to a local database takes only milliseconds to execute and adding a new table to a SELECT query doesn’t change the overall picture much, calling external services requires network communication. Which is unpredictable and even when firmly reliable, still slow.
As a rule of thumb, when serving a client request, a microservice shouldn’t be calling more than one external service. Ideally, you shouldn’t call any to avoid latency hits.
But how the front-end microservice would get the data to serve the customers then? The trick here is to have all that data prepared upfront. In order to do it, you need to maintain a dedicated storage on the front-end with a copy of all data it might be interested in from the others. And to maintain the consistency, you also need to subscribe the front-end to any changes from those 3 microservices.
This essentially makes the communication model between the front-end microservice and the others asynchronous. Instead of synchronously requesting the latest data from the 3 services every time the client needs a list of products, we maintain a local copy and keep it updated using domain events:
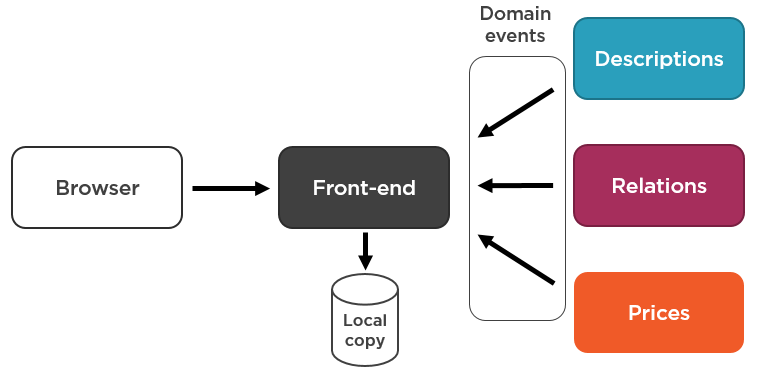
This approach eliminates the need for synchronous communication between the front-end and other microservices. It’s also perfectly scalable as you can add any number of additional microservices to the mix. All domain events are processed in the background anyway, so it doesn’t affect latency.
This manual "join" has its own drawbacks of course. First of all, it’s not as flexible as the ad hoc SQL query. You can’t change the set of services you gather information from as easily as you do with database tables. You’d need to modify domain event subscriptions and change the corresponding code that processes those events. You’d also need to change the local storage to reflect the new shape of the data you keep on the front-end.
The other drawback here is that you need to duplicate data. There’s no way around this as you have to maintain the local storage on the front-end microservice. It’s not as bad as it seems, though. It’s fine to have such duplicates as long as you are clear about which service is the master of that data. Make sure that only the master is allowed to change it, all other microservices should merely subscribe to those changes via domain events and update their copies accordingly.
Another thing to keep in mind here is that the downstream microservices should have only the minimum amount of data in their replicas. No need to copy everything. In our example, the front-end should store only those fields that are shown to the user, nothing more.
All these shortcomings are a common price you pay when going the microservices route. It is part of what Martin Fowler calls Microservice Premium - additional maintenance tax that you as a developer have to pay for everything.
By the way, there’s nothing inherently good or bad in either the microservice or monolith approach. The microservice premium is manageable, you just need to be aware of it when deciding on which way to evolve your application.
There’s a good rule of thumb when it comes to developing a large-scale greenfield project. If you are certain about the boundaries of your subdomains (i.e. you know the problem domain really well and already know the best way to split it into cohesive pieces), then choose the microservice route right away. If not, go with a well-structured monolith, figure out the boundaries along the way and only after that extract microservices out of it. Or keep it as is provided that its complexity is manageable.
Summary
When dealing with microservices, you cannot apply the same approach to gathering information from them as you do having a single relational database at hand.
-
Keep the local storage of all data needed to serve client requests.
-
Maintain consistency of that storage by subscribing to changes from upstream microservices.
-
Don’t call other microservices synchronously. Asynchronous calls (calls which are done in the background and where you don’t wait for a response) are OK.
- ← Specification Pattern in C# Pluralsight course
- How I tried to get into game development and failed →
Subscribe
Comments
comments powered by Disqus







