Email uniqueness as an aggregate invariant
Aggregates carry out many important functions. One of them is maintaining consistency boundaries. In this post, I write about the requirement of global email uniqueness and how it is related to aggregate invariants.
Consistency Boundary
The term Consistency Boundary basically means that the classes that comprise the aggregate must always be consistent as a group, no matter what you do with them. Consistency Boundary is what dictates the structure of your aggregates. Usually, you start with finding areas in your domain model which have some consistency requirements, and then define aggregate boundaries that will help you comply with those requirements.
Let’s say for example that you’ve got two entities - Plane and Ticket - and you need to make sure that no plane can be sold out with more than 10% overdraft.
If you put the two entities into their corresponding aggregates, it would be hard to enforce the requirement. Even if you do all proper checks, you can still get race conditions in multi-threaded scenarios (and mind you, almost every client-server application is multi-threaded on the server side). Two tickets within an almost fully booked plane can be sold simultaneously, and although each transaction will perform required validations, the limit would still be exceeded.
The only way to avoid such things is to implement locking. You can put both entities into a single aggregate, declare Plane an aggregate root, and introduce a version field into it which would change every time you modify anything in the aggregate. This version then can be used in an optimistic lock: when saving the aggregate, you need to check that its version in the database is the same as in your in-memory copy, and if it is not, return an error to the user.
Even if you are willing to forgo multi-threaded scenarios and take the risk of getting race conditions, it is still much easier to comply with consistency requirements when you gather entities into aggregates. In this case, all information needed to perform validations, as well as the validations themselves, can be gathered in a single place which simplifies reasoning about them.
Email uniqueness as an aggregate invariant
Let’s now say that you’ve got another consistency requirement. Suppose you have a User entity with an Email attribute, and you need to ensure the email uniqueness across all users in your system.
One way to meet this requirement is to put the corresponding invariant to the User class itself, like this:
public class User : Entity
{
public string Email { get; protected set; }
public void UpdateEmail(string newEmail)
{
User user = Database.GetUserByEmail(newEmail);
if (user != null && user != this)
throw new InvalidOperationException();
Email = newEmail;
}
}
There’s a problem with this approach, however. While it seems like we attribute relevant business logic to the domain class, this class now interferes with the outside world. The User entity refers to the database in order to get information about other existing users which means it is no longer properly isolated.
At first glance, it seems like we have a conflict here. On one hand, we have to break the domain model’s isolation in order to gather all relevant invariants under the User class. On the other hand, if we want to preserve the purity, we need to remove an important piece of domain knowledge from the corresponding entity thus potentially leaking it somewhere.
So, what to do? Are we stuck here?
Not at all. The dilemma I posed above is false. It’s based on the assumption that aggregates should be responsible for keeping hold of any invariants that are somehow related to that aggregate.
That is not the case. In reality, aggregates are only responsible for invariants that are fully confined to data from separate aggregate instances. They shouldn’t be responsible for invariants that span across multiple instances. In other words, a user must take charge of what is happening to that particular user only, it cannot possibly know about the other users.
Here’s how we can depict an invariant that involves information from multiple aggregate instances:
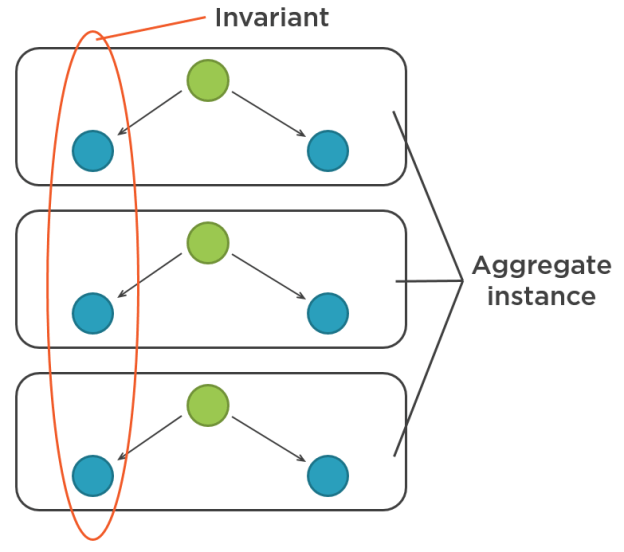
In the example with the emails, we need to look at all existing users in order to fulfill the uniqueness requirement.
This kind of invariants shouldn’t be attributed to aggregates. The only type of invariants they should be responsible for is those they have enough information to make a judgment about:
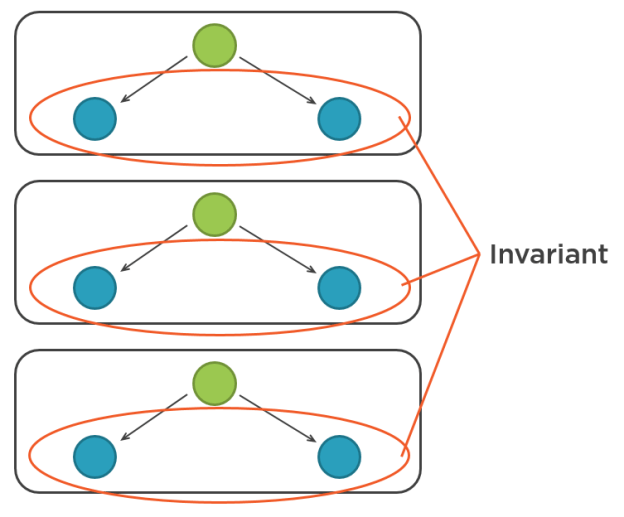
So, where should we handle invariants that cross the aggregate boundary then?
Once again, this is where domain services can help us. We can put such a consistency requirement to a User Service. It would collect all necessary data from the external sources and form an informative judgement regarding whether or not the user email can be changed.
And, as I mentioned in a previous post, it’s fine to attribute this responsibility to an application service too, without taking the trouble of introducing a separate domain service, as long as the application service itself is simple enough and this domain logic is not duplicated across your code base.
Summary
-
Aggregates are responsible for maintaining consistency boundaries.
-
There are two types of invariants: those that are confined to separate aggregate instances and those that span across all of them.
-
The first type should be attributed to aggregates.
-
Invariants of the second type should be handled by domain or application services.
Subscribe
Comments
comments powered by Disqus







