Combining SQL Server and MongoDB using NHibernate
We often think that relational and NoSQL databases are somewhat incompatible. But what if we could use both within a single domain model? I’d like to show how to combine SQL Server and MongoDB together and discuss what benefits we could get from it.
The problem
Relational databases is a good choice for many software development projects, but there are some particular use cases they are not very good at.
One of such use cases is many-to-many relations. I think it is the toughest moment in the overall picture of the paradigm mismatch between OOP and relational stores. Converting hierarchical data structures into flat tables requires quite a bit of work and thus usually appears to be an expensive operation.
The problem emerges when the number of relations exceeds some limit. And that limit is usually quite moderate.
Let’s take a concrete example. Let’s say we need to model a network of nodes with relations between them:
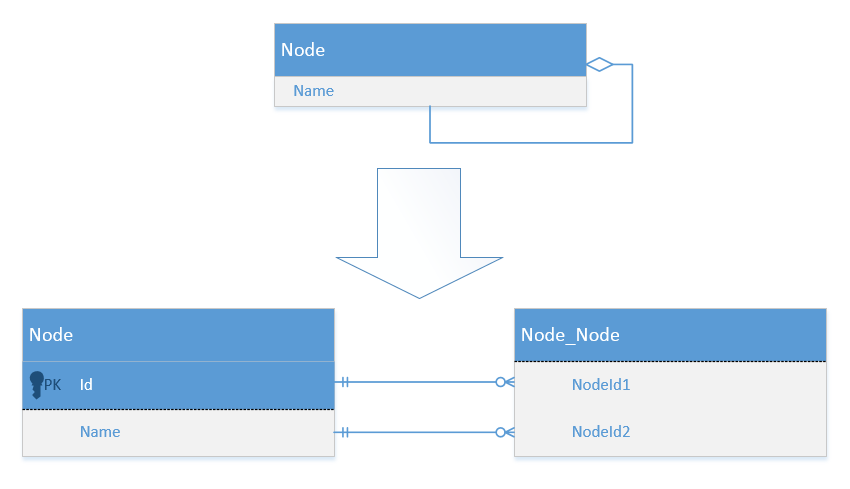
On the application side, the code can look as simple as this:
public class Node
{
public int Id { get; private set; }
public string Name { get; private set; }
public List<Node> Links { get; private set; }
public Node(string name)
{
Name = name;
Links = new List<Node>();
}
public void AddLink(Node node)
{
Links.Add(node);
node.Links.Add(this);
}
}
On the database side, we just need two tables to handle this situation: one for nodes themselves and the other for links between them.
If a typical node has not more than, say, twenty connections to other nodes, this solution works well in terms of performance and scalability. The performance becomes worse with a larger number of connections. And if there are thousands of them, it degrades drastically.
Okay, so how could we mitigate the problem? The reason why the performance got bad is that in order to persist the data, we need to flatten it first. This solution leads to creating N+1 rows in the database: one for the node and N for its connections.
If we could store all the data associated with a node in a single row, that could potentially solve our problem.
Bringing MongoDB in
Here’s where NoSQL databases come into play. They introduce the concept of document which is exactly what we need here. We can store all the information attached to a node within a single document and thus eliminate the need of flattening the data.
Of course, theoretically, we could just move all the data to some NoSQL storage, but what if we don’t want to get rid of our relational database completely? How can we combine them together?
Using an ORM, of course! NHibernate has a lot of extension points we can resort to in order to mix our own custom logic in the process of saving and retrieving data. With it, we can override the default persistence behavior for certain entities. We can store nodes in SQL Server just as we did before. Their links, at the same time, can be persisted in MongoDB.
Let’s see how we can do it. First, we need to register an event listener that is being executed after a node is loaded:
private static ISessionFactoryBuildSessionFactory(string connectionString)
{
FluentConfiguration configuration = Fluently.Configure()
.Database(MsSqlConfiguration.MsSql2012.ConnectionString(connectionString))
.Mappings(m => m.FluentMappings.AddFromAssembly(Assembly.GetExecutingAssembly()))
.ExposeConfiguration(x =>
{
x.EventListeners.PostLoadEventListeners = new IPostLoadEventListener[]
{
new EventListener()
};
});
return configuration.BuildSessionFactory();
}
This event listener builds the node up with the links from MongoDB:
internal class EventListener : IPostLoadEventListener
{
public void OnPostLoad(PostLoadEvent ev)
{
var networkNode = ev.EntityasMongoNode;
if (networkNode == null)
return ;
var repository = new NodeLinkRepository();
IList<NodeLink> linksFromMongo = repository.GetLinks(networkNode.Id);
HashSet<NodeLink> links = (HashSet<NodeLink>)networkNode
.GetType()
.GetProperty("LinksInternal", BindingFlags.NonPublic | BindingFlags.Instance)
.GetValue(networkNode);
links.UnionWith(linksFromMongo);
}
}
To save the links, we need to use an interceptor:
internal static ISessionOpenSession()
{
return _factory.OpenSession(new Interceptor());
}
internal class Interceptor : EmptyInterceptor
{
public override void PostFlush(ICollection entities)
{
IEnumerable<MongoNode> nodes = entities.OfType<MongoNode>();
if (!nodes.Any())
return ;
var repository = new NodeLinkRepository();
Task[] tasks = nodes.Select(x => repository.SaveLinks(x.Id, x.Links)).ToArray();
Task.WaitAll(tasks);
}
}
The PostFlush method is being called every time NHibernate is done synchronizing objects in memory with the database. If any exception takes place during storing data in SQL Server (due to, for example, unique constraint violation), we don’t get the links saved in MongoDB.
For saving part, we could also use an event listener, but interceptors have an advantage here which is the ability to process all nodes in a single batch as MongoDB driver allows us to access the database asynchronously.
You can find the full source code on GitHub.
Performance comparison of the two solutions
Okay, so what are the performance benefits, exactly? I have executed some performance tests. For them, I used the most common use cases for this domain model which are creating links between nodes and fetching an existing node with all its links into memory. I created 1000 nodes and linked them with each other. After that, I loaded each of them into memory one by one.
Here are the average results for 10 runs on my machine (the results are displayed in seconds):
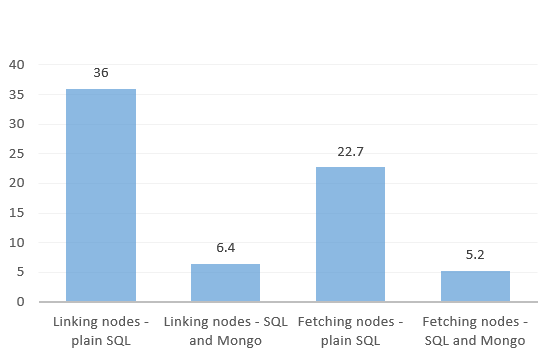
As you can see, the hybrid solution that uses both SQL Server and MongoDB is almost 6 times more performant on saves and more than 4 times faster on reads than the one with SQL Server only.
And there’s still some room for further performance optimization with MongoDB. Actually, I was able to increase the performance of writes by 1.5 times by executing them in batches using PLINQ. That gives us about 8.5x performance speedup on writes. The only problem with the use of PLINQ is that such approach is unstable due to some problems with the connection pooling in MongoDB driver. That might be changed after the issue is fixed.
SQL Server and MongoDB: limitations
There are some limitations in this approach.
Firstly, as we store data in different databases, we can’t use transactions and thus, lose the benefits they introduce. While the links are not getting stored if an exception takes place on the SQL Server side, the otherwise is not true. That means that, in order to revert the SQL Server update after an exception on the MongoDB side, we need to introduce some compensation logic.
Secondly, MongoDB limits the size of documents to 16 Mb each, so if you want to store more than 16Mb of links for each node, you need to flatten the structure of the collections in MongoDB and thus lose some performance benefits. Frankly, 16 Mb is quite a lot, so I don’t think this particular limitation is a deal breaker for any but the largest projects.
Summary
Combining SQL Server with MongoDB using NHibernate can be a good solution if you have lots of hierarchical data and don’t want to get rid of your relational database completely. It can help you to significantly increase the performance in the cases relational databases are not very good at.
You can find the full source code for this tutorial on GitHub.
Subscribe
Comments
comments powered by Disqus







