Shared library vs Enterprise development
Most of the development principles are applicable to any software you might develop. Nevertheless, there are some differences between building a reusable library and an enterprise application. Those differences often become sticking points as we try to apply experience gained in one type of project to projects of the other type.
The differences between shared library and enterprise development grow from differences in requirements and lifetime support cycle.
Difference #1: External clients
A typical shared library, by its definition, has a lot of dependents that you can’t control. That means that libraries face much stronger backward compatibility requirements then typical enterprise development does.
With an in-house software development, you can change, add or even remove public interfaces without bothering how it would affect the clients. All you need to do is change the clients along with the services. And when I write "interface" I mean interface in a broad sense: every public method in every public class is a part of the service’s interface.
With a library development, you need to support your clients in such a way that they can use the latest version of your library without (or with minimal) changes in their code. Failing to do so may lead to decrease of your customers' loyalty, and thus, to shortening your user base.
Difference #2: Deployment frequency
Another important difference is deployment frequency. You can’t ship a new version of your library every week. Even if you do, your clients won’t update it so frequently.
That makes some of the practices (for example, continuous delivery) used in enterprise world completely useless for a library development.
Difference #3: Source code accessibility
Users of your library typically can’t change the source code. Even if it’s open source, the effort required to change something in it is much larger.
Not only do you have to download, change and rebuild it, but you have to maintain the change all over the library’s lifespan, or at least until you decide to not use it anymore.
Pull request are not always accepted, so in order to keep the change, the client will need to apply it every time a new version comes out.
The points described lead to some significant differences in the development process.
Consequence #1: Open-Closed principle
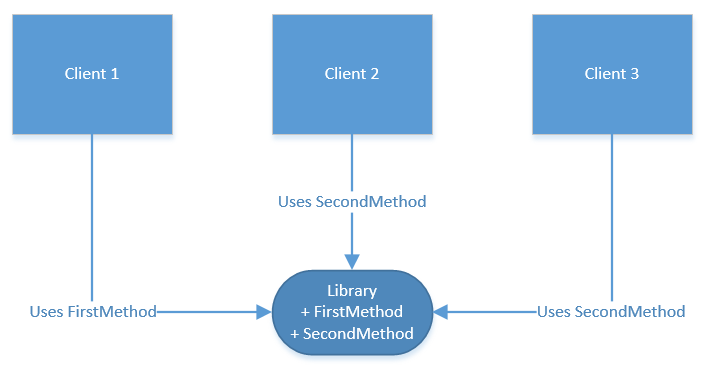
When you develop a library, you need to adhere to the following rule: once published, interfaces cannot be changed. That is, to support older versions of your clients, you should keep the previous implementation even if you have a better one. This rule is also known as Open-Closed principle as it was described by Bertrand Meyer in his Object-Oriented Software Construction book.
To introduce a change in a published interface, you should create a new interface that will reside side-by-side with the old one. The obsolete methods may be marked with an attribute so that the clients will get a warning telling them they should switch to newer version:
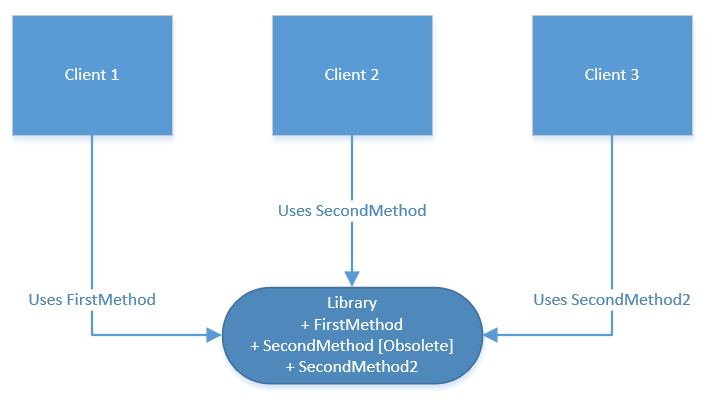
As you can’t force your clients to update their code other than by breaking backward compatibility, the obsolete interfaces may remain in your library for a long time, maybe forever.
Consequence #2: Thinking ahead vs YAGNI
Probably the most valuable principle in software development is the one called You Are Not Gonna Need It. Its basic idea is that you shouldn’t waste your time on features that you are not sure will be required and focus on the functionality your users need right here and right now.
This principle lies on an empirical observation that in most cases, you can’t guess what the requirements should be and you will have to rewrite your feature anyway when the requirements become clear.
While this approach is an advisable way to develop an in-house software, you shouldn’t adhere to it with library development. With library development, you should always think at least a little bit ahead of current needs because users of your library won’t be able to update it as frequently as you might want them to.
To illustrate it, I’ll give a simple example. Let’s assume that there is no DateTime class in .Net BCL so you are building a utility class to help you to work with dates. In your code, you need to find out what date will be in some number of days.
You write something like the following:
public class DateTime
{
public DateTime AddDays(double days) { /* Implementation */ }
}
If you develop an enterprise software and follow YAGNI principle, you just stop where you are and don’t implement anything else until you really need to. But with library development, you should think if there are any other similar functions your users might find useful. Of course, you can’t just implement everything your users might ever want. You still need to keep a balance, but the balance here is shifted to the "think ahead" part of the spectrum.
In the example above, you can’t just ship the library with this method along. There definitely are some other methods users will need if they utilize such kind of functionality:
public class DateTime
{
public DateTime AddDays(double days) { /* Implementation */ }
public DateTime AddMonths(double days) { /* Implementation */ }
public DateTime AddYears(double days) { /* Implementation */ }
public DateTime AddHours(double days) { /* Implementation */ }
public DateTime AddMinutes(double days) { /* Implementation */ }
public DateTime AddSeconds(double days) { /* Implementation */ }
}
Another example is the use of properties. Technically, there is no difference between this class:
public class MyClass
{
public string Name { get; set; }
}
and this class:
public class MyClass
{
public string Name;
}
With enterprise development, if you ever need to encapsulate Name field (so that the assignment will, for example, notify subscribers about the change), you can just turn the field into a property:
public class MyClass
{
private string _name;
public string Name
{
get { return _name; }
set
{
_name = value;
Notify();
}
}
}
Everything will work perfectly because the clients of this code will be recompiled together with the class itself.
On the other hand, if you develop a library, such approach will not work. Turning field into property breaks backward compatibility: the clients depending on this code will have to be recompiled in order to use the new version of the library. And that is not always an option. To comply with possible future changes, a library should use public properties instead of public fields from the very beginning.
I hope you can see now that you can’t and shouldn’t equally apply YAGNI to both enterprise and library development.
Consequence #3: Defensive programming
Defensive programming is a programming style aimed to predict any potential error in the code. In practice, it basically means validating the input and output parameters:
public void ProcessReport(string reportId, string userId)
{
if (reportId != null)
throw new ArgumentException("reportId");
if (userId != null)
throw new ArgumentException("userId");
User user = _userRepository.GetById(userId);
Report report = _reportRepository.GetById(userId);
if (user == null)
throw new ArgumentException("User is not found");
if (report == null)
throw new ArgumentException("Report is not found");
report.Process(user);
}
It’s a good practice to use such approach when you develop a library. Your clients won’t be able to step through your code (or at least it would be hard for them to do so) and debug it in case something goes wrong. That’s why it’s a good idea to provide them with as complete description as possible.
On the other hand, defensive programming brings a lot of complexity as you have to write much more code to maintain the validations. With an in-house development, you can keep the contract validation and just remove the other checks altogether:
public void ProcessReport(string reportId, string userId)
{
if (reportId != null)
throw new ArgumentException("reportId");
if (userId != null)
throw new ArgumentException("userId");
User user = _userRepository.GetById(userId);
Report report = _reportRepository.GetById(userId);
report.Process(user);
}
There’s little difference in whether you get an ArgumentException with a nice description or just a NullReferenceException. In both cases, they will be thrown at the same line of code. And you will also have a nice clue of what is going on in both cases.
When you develop enterprise software, there’s no need to stick to defensive programming as it doesn’t pay off.
Summary
You should always keep in mind what type of software you develop. Principles that are applicable to an in-house software development, don’t fit library development.
Don’t stick to YAGNI with a library as you will need to think at least a little bit ahead; practice defensive programming as you need to provide as many details as possible if something goes wrong.
The opposite is also true. Do stick to YAGNI with an enterprise development and don’t pay too much attention to defensive style if you don’t have external clients.
Subscribe
Comments
comments powered by Disqus






